Метод экспоненциального сглаживания пример. Прогнозирование методом экспоненциального сглаживания (ES, exponential smoothing)
1. Основные методические положения.
В методе простого экспоненциального сглаживания применяется взвешенное (экспоненциально) скользящее усреднение всех данных предыдущих наблюдений. Эта модель чаще всего применяется к данным, в которых необходимо оценить наличие зависимости между анализируемыми показателями (тренда) или зависимость анализируемых данных. Целью экспоненциального сглаживания является оценка текущего состояния, результаты которого определят все последующие прогнозы.
Экспоненциальное сглаживание предусматривает постоянное обновление модели за счет наиболее свежих данных. Этот метод основывается на усреднении (сглаживании) временных рядов прошлых наблюдений в нисходящем (экспоненциально) направлении. То есть более поздним событиям присваивается больший вес. Вес присваивается следующим образом: для последнего наблюдения весом будет величина α, для предпоследнего – (1-α), для того, которое было перед ним, - (1-α) 2 и т.д.
В сглаженном виде новый прогноз (для периода времени t+1) можно представлять как взвешенное среднее последнего наблюдения величины в момент времени t и ее прежнего прогноза на этот же период t. Причем вес α присваивается наблюдаемому значению, а вес (1- α) – прогнозу; при этом полагается, что 0< α<1. Это правило в общем виде можно записать следующим образом.
Новый прогноз = [α*(последнее наблюдение)]+[(1- α)*последний прогноз]
где - прогнозируемое значение на следующий период;
α – постоянная сглаживания;
Y t – наблюдение величины за текущий период t;
Прежний сглаженный прогноз этой величины на период t.
Экспоненциальное сглаживание – это процедура для постоянного пересмотра результатов прогнозирования в свете самых последних событий.
Постоянная сглаживания α является взвешенным фактором. Ее реальное значение определяется тем, в какой мере текущее наблюдение должно влиять на прогнозируемую величину. Если α близко к 1, значит в прогнозе существенно учитывается величина ошибки последнего прогнозирования. И наоборот, при малых значениях α прогнозируемая величина наиболее близка к предыдущему прогнозу. Можно представить как взвешенное среднее значение всех прошлых наблюдений с весовыми коэффициентами, экспоненциально убывающими с «возрастом» данных.
Таблица 2.1
Сравнение влияния разных значений постоянных сглаживания
Постоянная α является ключом к анализу данных. Если требуется, чтобы спрогнозированные величины были стабильны и случайные отклонения сглаживались, необходимо выбирать малое значение α. Большое значение постоянной α имеет смысл в том случае, если нужна быстрая реакция на изменения в спектре наблюдений.
2. Практический пример проведения экспоненциального сглаживания.
Представлены данные компании по объему продаж (тыс. шт.) за семь лет, постоянная сглаживания взята равной 0,1 и 0,6. Данные за 7 лет составляют тестовую часть; по ним необходимо оценить эффективность каждой из моделей. Для экспоненциального сглаживания рядов начальное значение берется равным 500 (первое значение фактических данных или среднее значение за 3 -5 периодов записывается в сглаженное значения за 2 квартал).
Таблица 2.2
Исходные данные
| Время | Действительное значение (фактическое) | Сглаженное значение | Ошибка прогноза | ||
| год | квартал | 0,1 | 0,1 | ||
| Excel | по формуле | ||||
| #Н/Д | 0,00 | ||||
| 500,00 | -150,00 | ||||
| 485,00 | 485,00 | -235,00 | |||
| 461,50 | 461,50 | -61,50 | |||
| 455,35 | 455,35 | -5,35 | |||
| 454,82 | 454,82 | -104,82 | |||
| 444,33 | 444,33 | -244,33 | |||
| 419,90 | 419,90 | -119,90 | |||
| 407,91 | 407,91 | -57,91 | |||
| 402,12 | 402,12 | -202,12 | |||
| 381,91 | 381,91 | -231,91 | |||
| 358,72 | 358,72 | 41,28 | |||
| 362,84 | 362,84 | 187,16 | |||
| 381,56 | 381,56 | -31,56 | |||
| 378,40 | 378,40 | -128,40 | |||
| 365,56 | 365,56 | 184,44 | |||
| 384,01 | 384,01 | 165,99 | |||
| 400,61 | 400,61 | -0,61 | |||
| 400,55 | 400,55 | -50,55 | |||
| 395,49 | 395,49 | 204,51 | |||
| 415,94 | 415,94 | 334,06 | |||
| 449,35 | 449,35 | 50,65 | |||
| 454,41 | 454,41 | -54,41 | |||
| 448,97 | 448,97 | 201,03 | |||
| 469,07 | 469,07 | 380,93 |
На рис. 2.1 представлен прогноз на основе экспоненциального сглаживания с постоянной сглаживания, равной 0,1.
 |
|||
Рис. 2.1. Экспоненциальное сглаживание
Решение в Excel.
1. Выберите меню «Сервис» – «Анализ данных». В списке «Инструменты анализа» выберите значение «Экспоненциальное сглаживание». Если в меню «Сервис» нет анализа данных, то необходимо установить «Пакет анализа». Для этого найти в «Параметрах» пункт «Настройки» и в появившемся диалоговом окне установить флажок на «Пакет анализа», нажать ОК.
2. На экране раскроется диалоговое окно, представленное на рис. 2.2.
3. В поле «входной интервал» введите значения исходных данных (плюс одна свободная ячейка).
4. Установите флажок «метки» (если в диапазоне ввода указаны названия столбцов).
5. Введите в поле «фактор затухания» значение (1-α).
6. В поле «входной интервал» введите значение ячейки, в которой хотели бы увидеть полученные значения.
7. Установите флажок «Опции» - «Вывод графика» для автоматического его построения.

Рис. 2.2. Диалоговое окно для экспоненциального сглаживания
3. Задание лабораторной работы.
Имеются исходные данные об объемах добычи нефтедобывающего предприятия за 2 года, представленные в таблице 2.3:
Таблица 2.3
Исходные данные
Проведите экспоненциальное сглаживание рядов. Коэффициент экспоненциального сглаживания примите равным 0,1; 0,2; 0,3. Полученные результаты прокомментируйте. Можно использовать статистические данные, представленные в приложении 1.
к.э.н., директор по науке и развитию ЗАО "КИС"
Метод экспоненциального сглаживания
Освоение новых и анализ известных управленческих технологий, которые позволяют повысить эффективность управления бизнесом, становится особенно актуальным для российских предприятий в настоящее время. Один из наиболее популярных инструментов - система бюджетирования, которая базируется на формировании бюджета предприятия с последующим контролем исполнения. Бюджет представляет собой сбалансированные краткосрочные коммерческие, производственные, финансовые и хозяйственные планы развития организации. Бюджет предприятия содержит целевые показатели, которые рассчитываются на основании прогнозных данных. Наиболее значимым прогнозом при составлении бюджета для любого предприятия является прогноз продаж. В предыдущих статьях был проведен анализ аддитивной и мультипликативной модели и рассчитан прогнозный объем продаж на следующие периоды.
При анализе временных рядов использовался метод скользящей средней, в котором все данные независимо от периода их возникновения являются равноправными. Существует другой способ, в котором данным приписываются веса, более поздним данным придается больший вес, чем более ранним.
Метод экспоненциального сглаживания в отличие от метода скользящих средних еще и может быть использован для краткосрочных прогнозов будущей тенденции на один период вперед и автоматически корректирует любой прогноз в свете различий между фактическим и спрогнозированным результатом. Именно поэтому метод обладает явным преимуществом над ранее рассмотренным.
Название метода происходит из того факта, что при его применении получаются экспоненциально взвешенные скользящие средние по всему временному ряду. При экспоненциальном сглаживании учитываются все предшествующие наблюдения - предыдущее учитывается с максимальным весом, предшествующее ему - с несколько меньшим, самое ранее наблюдение влияет на результат с минимальным статистическим весом.
Алгоритм расчета экспоненциально сглаженных значений в любой точке ряда i основан на трех величинах :
фактическое значение Ai в данной точке ряда i,
прогноз в точке ряда Fi
некоторый заранее заданный коэффициент сглаживания W, постоянный по всему ряду.
Новый прогноз можно записать формулой:
Расчет экспоненциально сглаженных значений
При практическом использовании метода экспоненциального сглаживания возникает две проблемы: выбор коэффициента сглаживания (W), который в значительной степени влияет на результаты и определение начального условия (Fi). С одной стороны, для сглаживания случайных отклонений величину нужно уменьшать. С другой стороны, для увеличения веса новых измерений нужно увеличивать.
Хотя, в принципе, W может принимать любые значения из диапазона 0 < W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Выбор коэффициента постоянной сглаживания является субъективным. Аналитики большинства фирм при обработке рядов используют свои традиционные значения W. Так, по опубликованным данным в аналитическом отделе Kodak, традиционно используют значение 0,38, а на фирме Ford Motors - 0,28 или 0,3.
Ручной расчет экспоненциального сглаживания требует крайне большого объема монотонной работы. На примере рассчитаем прогнозный объем на 13 квартал, если имеются данные объема продаж за последние 12 кварталов, используя метод простого экспоненциального сглаживания.
Предположим, что на первый квартал прогноз продаж составил 3. И пусть коэффициент сглаживания W =0,8.
Заполним в таблице третий столбец, подставляя для каждого последующего квартала значение предыдущего по формуле:
Для 2 квартала F2 =0,8*4 (1-0,8)*3 =3,8
Для 3 квартала F3 =0,8*6 (1-0,8)*3,8 =5,6
Аналогично, рассчитывается сглаженное значение для коэффициента 0,5 и 0,33.
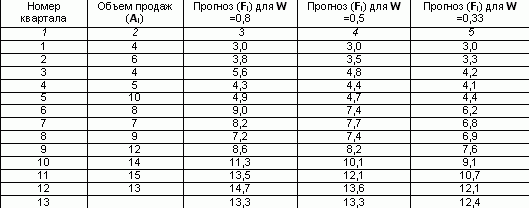
Расчет прогноза
объема
продаж
Прогноз объема продаж при W = 0.8 на 13 квартал составил 13.3 тыс.руб.
Эти данные можно представить в графической форме:

Экспоненциальное сглаживание
02.04.2011 – Стремление человека приподнять завесу грядущего и предвидеть ход событий имеет такую же длинную историю, как и его попытки, понять окружающий мир. Очевидно, что в основе интереса к прогнозу лежат достаточно сильные жизненные мотивы (теоретические и практические). Прогноз выступает в качестве важнейшего метода проверки научных теорий и гипотез. Способность предвидеть будущее является неотъемлемой стороной сознания, без которой была бы невозможна сама человеческая жизнь.
Понятие “прогнозирование” (от греч. prognosis – предвидение, предсказание) означает процесс разработки вероятностного суждения о состоянии какого-либо явления или процесса в будущем, это познание того, чего еще нет, но что может наступить в ближайшее или отдаленное время.
Прогноз по своему содержанию более сложен, чем предсказание. Он, с одной стороны, отражает наиболее вероятное состояние объекта, а с другой – определяет пути и средства достижения желаемого результата. На основе полученной прогнозным путем информации по достижению желаемой цели, принимаются определенные решения.
Необходимо отметить, что динамика экономических процессов в современных условиях отличается нестабильностью и неопределенностью, что затрудняет применение традиционных методов прогнозирования.
Модели экспоненциального сглаживания и прогнозирования относятся к классу адаптивных методов прогнозирования, основной характеристикой которых является способность непрерывно учитывать эволюцию динамических характеристик изучаемых процессов, подстраиваться под эту динамику, придавая, в частности, тем больший вес и тем более высокую информационную ценность имеющимся наблюдениям, чем ближе они расположены к текущему моменту времени. Смысл термина состоит в том, что адаптивное прогнозирование позволяет обновлять прогнозы с минимальной задержкой и с помощью относительно несложных математических процедур.
Метод экспоненциального сглаживания был независимо открыт Брауном (Brown R.G. Statistical forecasting for inventory control, 1959) и Хольтом (Holt C.C. Forecasting Seasonal and Trends by Exponentially Weighted Moving Averages, 1957). Экспоненциальное сглаживание, как и метод скользящих средних, для прогноза использует прошлые значения временного ряда.
Сущность метода экспоненциального сглаживания заключается в том, что временной ряд сглаживается с помощью взвешенной скользящей средней, в которой веса подчиняются экспоненциальному закону. Взвешенная скользящая средняя с экспоненциально распределенными весами характеризует значение процесса на конце интервала сглаживания, то есть является средней характеристикой последних уровней ряда. Именно это свойство и используется для прогнозирования.
Обычное экспоненциальное сглаживание применяется в случае отсутствия в данных тренда или сезонности. В этом случае прогноз является взвешенной средней всех доступных предыдущих значений ряда; веса при этом со временем геометрически убывают по мере продвижения в прошлое (назад). Поэтому (в отличие от метода скользящего среднего) здесь нет точки, на которой веса обрываются, то есть зануляются. Прагматически ясная модель простого экспоненциального сглаживания может быть записана следующим (по представленной ссылке можно скачать все формулы статьи):
Покажем экспоненциальный характер убывания весов значений временного ряда – от текущего к предыдущему, от предыдущего к пред–предыдущему и так далее:
Если формула применяется
рекурсивно, то каждое новое сглаженное значение (которое является также
прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного
ряда. Очевидно, что результат сглаживания зависит от параметра адаптации альфа
.
Его можно интерпретировать как коэффициент дисконтирования, характеризующий
меру девальвации данных за единицу времени. Причем влияние данных на прогноз
экспоненциально убывает с “возрастом” данных. Зависимость влияния данных на
прогноз при разных коэффициентах альфа
приведена на рисунке 1.

Рисунок 1. Зависимость влияния данных на прогноз при разных коэффициентах адаптации
Следует заметить, что значение сглаживающего параметра не может равняться 0 или 1, так как в этом случае сама идея экспоненциального сглаживания отвергается. Так, если альфа равняется 1, то прогнозное значение F t+1 совпадает с текущим значением ряда Хt , при этом экспоненциальная модель стремится к самой простой “наивной” модели, то есть в этом случае прогнозирование является абсолютно тривиальным процессом. Если альфа равняется 0, то начальное прогнозное значение F 0 (initial value ) одновременно будет являться прогнозом для всех последующих моментов ряда, то есть прогноз в этом случае будет выглядеть в виде обычной горизонтальной линии.
Тем не менее, рассмотрим варианты сглаживающего параметра, близкие к 1 или 0. Так, если альфа близко к 1, то предыдущие наблюдения временного ряда практически полностью игнорируются. В случае если альфа близко к 0, то игнорируются уже текущие наблюдения. Значения альфа между 0 и 1 дают промежуточные результаты. По мнению ряда авторов, оптимальное значение альфа находится в пределах от 0,05 до 0,30. Однако иногда альфа , большее 0,30, дает лучший прогноз.
В целом лучше оценивать оптимальное альфа по исходным данным (при помощи поиска по сетке), а не использовать искусственные рекомендации. Тем не менее, в случае если значение альфа , превышающее 0,3, минимизирует ряд специальных критериев, то это указывает на то, что другая техника прогнозирования (с применением тренда или сезонности) способна обеспечить еще более точные результаты. Для нахождения оптимального значения альфа (то есть минимизации специальных критериев) используется квазиньютоновский алгоритм максимизации правдоподобия (вероятности), который эффективнее обычного перебора на сетке.
Перепишем уравнение (1) в виде альтернативного варианта, позволяющего оценить, как модель экспоненциального сглаживания “обучается” на своих прошлых ошибках:
Из уравнения (3) ярко видно, что прогноз на период t+1 подлежит изменению в сторону увеличения, в случае превышения фактического значения временного ряда в период t над прогнозным значением, и, наоборот, прогноз на период t+1 должен быть уменьшен, если Х t меньше, чем F t .
Отметим, что при использовании методов экспоненциального сглаживания важным вопросом всегда является определение начальных условий (начального прогнозного значения F 0 ). Процесс выбора начального значения сглаженного ряда называется инициализацией (initializing ), или, иначе, “разогревом” (“warming up ”) модели. Дело в том, что начальное значение сглаженного процесса может существенным образом повлиять на прогноз для последующих наблюдений. С другой стороны, влияние выбора уменьшается с длиной ряда и становится некритичным при очень большом числе наблюдений. Браун впервые предложил использовать в качестве стартового значения среднее динамического ряда. Другие авторы предлагают использовать в качестве начального прогноза первое фактическое значение временного ряда.
В середине прошлого века Хольт предложил расширить модель простого экспоненциального сглаживания за счет включения в нее фактора роста (growth factor ), или иначе тренда (trend factor ). В результате модель Хольта может быть записана следующим образом:
Данный метод позволяет учесть присутствие в данных линейного тренда. Позднее были предложены другие виды трендов: экспоненциальный, демпфированный и др.
Винтерс предложил усовершенствовать модель Хольта с точки зрения возможности описания влияния сезонных факторов (Winters P.R. Forecasting Sales by Exponentially Weighted Moving Averages, 1960).
В частности, он далее расширил модель Хольта за счет включения в нее дополнительного уравнения, описывающего поведение сезонной компоненты (составляющей). Система уравнений модели Винтерса выглядит следующим образом:
Дробь в первом уравнении служит для исключения сезонности из исходного ряда. После исключения сезонности (по методу сезонной декомпозиции Census I ) алгоритм работает с “чистыми” данными, в которых нет сезонных колебаний. Появляются они уже в самом финальном прогнозе (15), когда “чистый” прогноз, посчитанный почти по методу Хольта, умножается на сезонную компоненту (индекс сезонности ).
Скользящая средняя позволяет прекрасно сглаживать данные. Но ее главный недостаток заключатся в том, что каждое значение в исходных данных для нее имеет одинаковый вес. Например, для средней скользящей использующей период шести недель каждому значению для каждой недели уделяется 1/6 веса. В случае некоторых собранных статистических данных более актуальным значениям присваивается больший вес. Поэтому экспоненциальное сглаживание применятся для того, чтобы придать самым актуальным данным большего веса. Таким образом решается данная статистическая проблема.
Формула расчета метода экспоненциального сглаживания в Excel
Ниже на рисунке изображен отчет спроса на определенный продукт за 26 недель. Столбец «Спрос» содержит информацию о количестве проданного товара. В столбце «Прогноз» – формула:
В столбце «Скользящая средняя» определяется прогнозируемый спрос, рассчитанный с помощью обычного вычисления скользящей средней с периодом 6 недель:

В последнем столбце «Прогноз», с описанной выше формулой применяется метод экспоненциального сглаживания данных в которых значения последних недель имеет больший вес чем предыдущих.
Коэффициент «Альфа:» вводится в ячейке G1, он значит вес присвоения наиболее актуальным данным. В данном примере он имеет значение 30%. Остальные 70% веса распределяется на остальные данные. То есть второе значение с точки зрения актуальности (с право на лево) имеет вес равный 30% от оставшихся 70% веса – это 21%, третье значение имеет вес равен 30% от остальной части 70% веса – 14,7% и так далее.
График экспоненциального сглаживания
Ниже на рисунке изображен график спроса, среднее скользящие и прогноз методом экспоненциального сглаживания, который построен на основе исходных значений:

Обратите внимание, что прогноз с экспоненциальным сглаживанием более активно реагирует на изменения спроса чем скользящая средняя линия.
Данные для очередных предыдущих недель умножаются на коэффициент альфа, а результат добавляется к оставшейся части процентов веса умноженный на предыдущее прогнозируемое значение.
Выявление и анализ тенденции временного ряда часто производится с помощью его выравнивания или сглаживания. Экспоненциальное сглаживание - один из простейших и распространенных приемов выравнивания ряда. Экспоненциальное сглаживание можно представить как фильтр, на вход которого последовательно поступают члены исходного ряда, а на выходе формируются текущие значения экспоненциальной средней.
Пусть - временной ряд.
Экспоненциальное сглаживание ряда осуществляется по рекуррентной формуле: , .
Чем меньше α, тем в большей степени фильтруются, подавляются колебания исходного ряда и шума.
Если последовательно использовать рекуррентное это соотношение, то экспоненциальную среднюю можно выразить через значения временного ряда X.
Если к моменту начала сглаживания существуют более ранние данные, то в качестве начального значения можно использовать арифметическую среднюю всех имеющихся данных или какой-то их части.
После появления работ Р. Брауна экспоненциальное сглаживание часто используется для решения задачи краткосрочного прогнозирования временных рядов.
Постановка задачи
Пусть задан временной ряд: .
Необходимо решить задачу прогнозирования временного ряда, т.е. найти
Горизонт прогнозирования, необходимо, чтобы
Для того, чтобы учитывать устаревание данных, введем невозрастающую последовательность весов , тогда
Модель Брауна
Предположим, что D - невелико (краткосрочный прогноз), то для решения такой задачи используют модель Брауна .
Если рассматривать прогноз на 1 шаг вперед, то - погрешность этого прогноза, а новый прогноз получается в результате корректировки предыдущего прогноза с учетом его ошибки - суть адаптации.
При краткосрочном прогнозировании желательно как можно быстрее отразить новые изменения и в то же время как можно лучше «очистить» ряд от случайных колебаний. Т.о. следует увеличивать вес более свежих наблюдений: .
С другой стороны, для сглаживания случайных отклонений, α нужно уменьшить: .
Т.о. эти два требования находятся в противоречии. Поиск компромиссного значения α составляет задачу оптимизации модели. Обычно, α берут из интервала (0,1/3).
Примеры

Работа экспоненциального сглаживания при α=0.2 на данных ежемесячных отчетов по продажам иностранной автомобильной марки в России за период с января 2007 по октябрь 2008. Отметим резкие падения в январе и феврале, когда продажи традиционно снижаются и повышения в начале лета.
Проблемы
Модель работает только при небольшом горизонте прогнозирования. Не учитываются тренд и сезонные изменения. Чтобы учесть их влияние, предлагается использовать модели: Хольта (учитывается линейный тренд) Хольта-Уинтерса (мультипликативные экспоненциальный тренд и сезонность), Тейла-Вейджа (аддетивные линейный тренд и сезонность).
Предыдущая статья: Чему равна скорость света Следующая статья: Углерод — характеристика элемента и химические свойства