A lottón alkalmazott Bayes-képlet. Önállóan megoldandó problémák
Ki az a Bayes? és mi köze ennek a menedzsmenthez? - következhet egy teljesen jogos kérdés. Egyelőre fogadjon szót: ez nagyon fontos!.. és érdekes (legalábbis számomra).
Mi az a paradigma, amelyben a legtöbb vezető működik: Ha megfigyelek valamit, milyen következtetéseket vonhatok le belőle? Mit tanít Bayes: minek kell valójában ott lennie, hogy megfigyelhessem ezt a valamit? Pontosan így fejlődik minden tudomány, és erről azt írja (emlékezetből idézek): akinek nincs a fejében elmélet, az egyik ötlettől a másikig visszariad a különféle események (megfigyelések) hatására. Nem hiába mondják: nincs gyakorlatiasabb egy jó elméletnél.
Példa a gyakorlatból. A beosztottam hibázik, és a kolléganőm (egy másik osztály vezetője) azt mondja, hogy a hanyag alkalmazotton vezetői befolyást kellene gyakorolni (vagyis megbüntetni/szidni). És tudom, hogy ez az alkalmazott havonta 4-5 ezer azonos típusú műveletet végez, és ezalatt legfeljebb 10 hibát követ el. Érzi a paradigma különbségét? A kolléga reagál a megfigyelésre, és eleve tudomásom van arról, hogy a munkavállaló bizonyos számú hibát vét, tehát egy másik nem befolyásolta ezt a tudást... Most, ha a hónap végén kiderül, hogy vannak, például 15 ilyen hiba!.. Ez már ok lesz arra, hogy tanulmányozzuk a szabványok be nem tartásának okait.
Meg van győződve a bayesi megközelítés fontosságáról? Érdekelt? remélem igen. És most a légy a kenőcsben. Sajnos a bayesi ötleteket ritkán adják azonnal. Őszintén megvallva nem volt szerencsém, hiszen ezen keresztül ismerkedtem meg ezekkel a gondolatokkal népszerű irodalom, melynek elolvasása után sok kérdés maradt. Amikor jegyzetírást terveztem, összegyűjtöttem mindent, amit korábban Bayes-en jegyzeteltem, és tanulmányoztam az interneten leírtakat is. Bemutatom a figyelmedbe a legjobb tippemet a témával kapcsolatban. Bevezetés a Bayes-féle valószínűségbe.
Bayes tételének levezetése
Tekintsük a következő kísérletet: megnevezzük a szakaszon lévő tetszőleges számot, és feljegyezzük, ha ez a szám például 0,1 és 0,4 között van (1a. ábra). Ennek az eseménynek a valószínűsége egyenlő a szegmens hosszának a szegmens teljes hosszához viszonyított arányával, feltéve, hogy a számok jelennek meg a szakaszon egyformán valószínű. Matematikailag ez leírható p(0,1 <= x <= 0,4) = 0,3, или кратко r(X) = 0,3, ahol r- valószínűség, X- valószínűségi változó a tartományban, X– valószínűségi változó a tartományban. Vagyis a szegmens eltalálásának valószínűsége 30%.

Rizs. 1. Valószínűségek grafikus értelmezése
Most vegyük figyelembe az x négyzetet (1b. ábra). Tegyük fel, hogy meg kell neveznünk számpárokat ( x, y), amelyek mindegyike nagyobb nullánál és kisebb egynél. Annak a valószínűsége x(első szám) a szegmensen belül lesz (kék terület 1), egyenlő a kék terület területének és a teljes négyzet területének arányával, azaz (0,4 – 0,1) * (1 – 0) ) / (1 * 1) = 0, 3, azaz ugyanaz a 30%. Annak a valószínűsége y a szegmensen belül (2. zöld terület) egyenlő a zöldterület területének és a teljes négyzet területének arányával p(0,5 <= y <= 0,7) = 0,2, или кратко r(Y) = 0,2.
Mit tanulhatsz meg egyszerre az értékekről? xÉs y. Például mennyi a valószínűsége annak, hogy ugyanakkor xÉs y a megfelelő adott szegmensekben vannak? Ehhez ki kell számítania a 3. terület (a zöld és kék csíkok metszéspontja) területének arányát a teljes négyzet területéhez: p(X, Y) = (0,4 – 0,1) * (0,7 – 0,5) / (1 * 1) = 0,06.
Tegyük fel, hogy tudni szeretnénk, mennyi ennek a valószínűsége y az if intervallumban van x már a tartományban van. Azaz valójában van egy szűrőnk, és amikor párokat hívunk ( x, y), akkor azonnal eldobjuk azokat a párokat, amelyek nem felelnek meg a megtalálás feltételének x adott intervallumban, majd a szűrt párokból azokat számoljuk, amelyekre y kielégíti feltételünket, és a valószínűséget azon párok számának arányának tekinti, amelyekhez y a fenti szegmensben található a szűrt párok teljes számához (vagyis amelyhez x szegmensben fekszik). Ezt a valószínűséget így írhatjuk fel p(Y|X at X elérje a lőtávolságot." Nyilvánvaló, hogy ez a valószínűség egyenlő a 3. terület és az 1. kék terület területének arányával. A 3. terület területe (0,4 – 0,1) * (0,7 – 0,5) = 0,06, és az 1. kék terület területe ( 0,4 – 0,1) * (1 – 0) = 0,3, akkor ezek aránya 0,06 / 0,3 = 0,2. Más szóval, a megtalálás valószínűsége y azon a szegmensen, feltéve, hogy x szegmenshez tartozik p(Y|X) = 0,2.
Az előző bekezdésben tulajdonképpen megfogalmaztuk az azonosságot: p(Y|X) = p(X, Y) / p( X). Ez így szól: „az elütés valószínűsége at tartományban, feltéve, hogy X találati tartomány, amely megegyezik az egyidejű találati valószínűség arányával X a tartományba és at a tartományra, az eltalálás valószínűségére X a tartományba."
Analógia alapján vegyük figyelembe a valószínűséget p(X|Y). Párokat hívunk ( x, y), és szűrje ki azokat, amelyekre y 0,5 és 0,7 között van, akkor annak a valószínűsége x abban az intervallumban van, feltéve, hogy y szegmenshez tartozik egyenlő a 3. régió területének és a 2. zöld régió területének arányával: p(X|Y) = p(X, Y) / p(Y).
Vegye figyelembe, hogy a valószínűségek p(X, Y) És p(Y, X) egyenlőek, és mindkettő egyenlő a 3. zóna területének a teljes négyzet területéhez viszonyított arányával, de a valószínűségek p(Y|X) És p(X|Y) nem egyenlők; míg a valószínűség p(Y|X) egyenlő a 3. régió és az 1. régió területének arányával, és p(X|Y) – a 3. régiótól a 2. régióig. Vegye figyelembe azt is p(X, Y) gyakran így jelölik p(X&Y).
Ezért két definíciót vezettünk be: p(Y|X) = p(X, Y) / p( X) És p(X|Y) = p(X, Y) / p(Y)
Írjuk át ezeket az egyenlőségeket a következő alakba: p(X, Y) = p(Y|X) * p( X) És p(X, Y) = p(X|Y) * p(Y)
Mivel a bal oldalak egyenlőek, a jobb oldalak egyenlőek: p(Y|X) * p( X) = p(X|Y) * p(Y)
Vagy átírhatjuk az utolsó egyenlőséget a következőképpen:

Ez Bayes tétele!
Az ilyen egyszerű (majdnem tautologikus) transzformációkból tényleg nagy tétel születik!? Ne siesse el a következtetéseket. Beszéljük meg újra, hogy mit kaptunk. Volt egy bizonyos kezdeti (a priori) valószínűség r(X), hogy a valószínűségi változó X a szegmensen egyenletesen eloszló tartományba esik X. Esemény történt Y, melynek eredményeként megkaptuk ugyanannak a valószínűségi változónak a posterior valószínűségét X: r(X|Y), és ez a valószínűség eltér ettől r(X) együtthatóval. Esemény Y bizonyítéknak nevezett, többé-kevésbé megerősítő vagy cáfoló X. Ezt az együtthatót néha nevezik bizonyíték ereje. Minél erősebb a bizonyíték, annál inkább megváltoztatja az Y megfigyelésének ténye a priori valószínűséget, annál inkább eltér a posterior valószínűség a priortól. Ha a bizonyíték gyenge, a posterior valószínűsége majdnem megegyezik a korábbival.
Bayes-képlet diszkrét valószínűségi változókra
Az előző részben levezettük a Bayes-képletet az intervallumon definiált folytonos x és y valószínűségi változókra. Tekintsünk egy példát diszkrét valószínűségi változókkal, amelyek mindegyike két lehetséges értéket vesz fel. A rutin orvosi vizsgálatok során kiderült, hogy negyven évesen a nők 1%-a szenved mellrákban. A rákos nők 80%-a pozitív mammográfiai eredményt kap. Az egészséges nők 9,6%-a pozitív mammográfiás eredményeket is kap. A vizsgálat során egy nő ebben a korcsoportban kapott pozitív mammográfiai eredményt. Mennyi az esélye, hogy valóban mellrákja van?
Az érvelés/számítás menete a következő. A rákos betegek 1%-a közül a mammográfia 80%-ban ad pozitív eredményt = 1% * 80% = 0,8%. Az egészséges nők 99%-ánál a mammográfia 9,6% pozitív eredményt ad = 99% * 9,6% = 9,504%. Összesen 10,304% (9,504% + 0,8%) pozitív mammográfiai eredménnyel, mindössze 0,8% beteg, a maradék 9,504% egészséges. Így annak a valószínűsége, hogy egy pozitív mammográfiás nő rákbeteg, 0,8% / 10,304% = 7,764%. 80%-ra gondoltál?
Példánkban a Bayes-képlet a következő formában jelenik meg:
Beszéljünk még egyszer ennek a képletnek a „fizikai” jelentéséről. X– valószínűségi változó (diagnózis), értékeket vesz fel: X 1- beteg és X 2- egészséges; Y– valószínűségi változó (mérési eredmény – mammográfia), értékek felvétele: I 1- pozitív eredmény és Y2- negatív eredmény; p(X 1)– a mammográfia előtti megbetegedés valószínűsége (a priori valószínűség) 1%; p(Y 1 |X 1 ) – a pozitív eredmény valószínűsége, ha a beteg beteg (feltételes valószínűség, mivel ezt a feladat feltételei között kell megadni), egyenlő 80%-kal; p(Y 1 |X 2 ) – a pozitív eredmény valószínűsége, ha a beteg egészséges (feltételes valószínűség is), 9,6%; p(X 2)– annak a valószínűsége, hogy a beteg egészséges a mammográfia előtt (a priori valószínűség), 99%; p(X 1|Y 1 ) – annak a valószínűsége, hogy a beteg beteg, pozitív mammográfiai eredmény esetén (posterior valószínűség).
Látható, hogy az utólagos valószínűség (amit keresünk) arányos az előzetes valószínűséggel (kezdeti) egy kicsit összetettebb együtthatóval  . Hadd hangsúlyozzam még egyszer. Véleményem szerint ez a bayesi megközelítés alapvető aspektusa. Mérés ( Y) hozzáadott egy bizonyos mennyiségű információt az eredetileg rendelkezésre állóhoz (a priori), ami pontosította az objektumról szerzett ismereteinket.
. Hadd hangsúlyozzam még egyszer. Véleményem szerint ez a bayesi megközelítés alapvető aspektusa. Mérés ( Y) hozzáadott egy bizonyos mennyiségű információt az eredetileg rendelkezésre állóhoz (a priori), ami pontosította az objektumról szerzett ismereteinket.
Példák
A feldolgozott anyag összevonásához próbáljon meg több problémát megoldani.
1. példa 3 urna van; az elsőben 3 fehér golyó és 1 fekete; a másodikban - 2 fehér golyó és 3 fekete; a harmadikban 3 fehér golyó van. Valaki véletlenszerűen megközelíti az egyik urnát, és kivesz belőle 1 labdát. Ez a labda fehérnek bizonyult. Határozza meg annak utólagos valószínűségét, hogy a golyót az 1., 2., 3. urnából húzzák.
Megoldás. Három hipotézisünk van: H 1 = (az első urna van kiválasztva), H 2 = (a második urna van kiválasztva), H 3 = (a harmadik urna van kiválasztva). Mivel az urnát véletlenszerűen választják ki, a hipotézisek a priori valószínűségei egyenlőek: P(H 1) = P(H 2) = P(H 3) = 1/3.
A kísérlet eredményeként megjelent az A = esemény (a kiválasztott urnából fehér golyót húztunk). Az A esemény feltételes valószínűségei a H 1, H 2, H 3 hipotézisek mellett: P(A|H 1) = 3/4, P(A|H 2) = 2/5, P(A|H 3) = 1. Például az első egyenlőség így hangzik: „a valószínűsége, hogy fehér golyót húzunk, ha az első urnát választjuk, 3/4 (mivel az első urnában 4 golyó van, és ebből 3 fehér).
Bayes képletével megtaláljuk a hipotézisek utólagos valószínűségét:

Így az A esemény bekövetkezésére vonatkozó információk tükrében a hipotézisek valószínűségei megváltoztak: a H 3 hipotézis lett a legvalószínűbb, a H 2 hipotézis a legkevésbé valószínű.
2. példa Két lövő egymástól függetlenül lő ugyanarra a célpontra, mindegyik egy lövést ad le. Az első lövő célba találásának valószínűsége 0,8, a másodiké 0,4. Lövés után egy lyukat fedeztek fel a célban. Határozza meg annak valószínűségét, hogy ez a lyuk az első lövőhöz tartozik (Az eredményt (mindkét lyuk egybeesett) el kell hagyni, mint elhanyagolhatóan valószínűtlen).
Megoldás. A kísérlet előtt a következő hipotézisek lehetségesek: H 1 = (sem az első, sem a második nyíl nem fog eltalálni), H 2 = (mindkét nyíl eltalál), H 3 - (az első lövész eltalálja, de a második nem ), H 4 = (az első lövöldöző nem fog eltalálni, a második pedig eltalálja). A hipotézisek előzetes valószínűségei:
P(H1)=0,2*0,6=0,12; P(H2)=0,8*0,4=0,32; P(H3)=0,8*0,6=0,48; P(H4)=0,2*0,4=0,08.
A megfigyelt esemény A = (egy lyuk van a célpontban) feltételes valószínűségei ezeknél a hipotéziseknél egyenlők: P(A|H 1) = P(A|H 2) = 0; P(A|H3) = P(A|H4) = 1
A kísérlet után a H 1 és H 2 hipotézisek lehetetlenné válnak, és a H 3 és H 4 hipotézisek utólagos valószínűsége a Bayes-képlet szerint:

Bayes a spam ellen
Bayes formulája széles körben alkalmazható a spamszűrők fejlesztésében. Tegyük fel, hogy meg akar tanítani egy számítógépet annak meghatározására, hogy mely e-mailek minősülnek spamnek. A szótárból és a kifejezésekből indulunk tovább Bayesi becslések segítségével. Először hozzuk létre a hipotézisek terét. Bármely betűvel kapcsolatban legyen két hipotézisünk: H A spam, H B nem spam, hanem egy normális, szükséges betű.
Először is „tanítsuk be” jövőbeli levélszemét-elhárító rendszerünket. Vegyük az összes meglévő betűt, és osszuk fel két, egyenként 10 betűs „halomra”. Tegyük az egyikbe a spam leveleket, és nevezzük H A kupacnak, a másikba pedig a szükséges levelezést és hívjuk H B kupacnak. Most pedig lássuk: milyen szavak és kifejezések találhatók a spamekben és a szükséges levelekben, és milyen gyakorisággal? Ezeket a szavakat és kifejezéseket bizonyítékoknak nevezzük, és E 1 , E 2 jelöléssel jelöljük... Kiderült, hogy a gyakran használt szavak (például a „tetszik”, „tiéd”) a H A és H B halmokban körülbelül a ugyanaz a frekvencia. Így ezeknek a szavaknak a jelenléte egy levélben semmit sem árul el arról, hogy melyik kupachoz rendeljük (gyenge bizonyíték). Adjunk ezekhez a szavakhoz semleges „spam” valószínűségi pontszámot, mondjuk 0,5-öt.
Az „angolul beszélt” kifejezés csak 10 betűben jelenjen meg, és gyakrabban a spam levelekben (például 10-ből 7 spamlevélben), mint a szükségesnél (10-ből 3-ban). Adjunk ennek a kifejezésnek magasabb minősítést a spamre: 7/10, és alacsonyabb értékelést a normál e-mailekre: 3/10. Ezzel szemben kiderült, hogy a „haver” szó gyakrabban fordult elő normál betűkkel (10-ből 6). És akkor kaptunk egy rövid levelet: „Barátom! Hogy beszélsz angolul?”. Próbáljuk meg értékelni a „spam” jellegét. Megadjuk az egyes kupacokhoz tartozó betűk P(H A), P(H B) általános becsléseit egy kissé leegyszerűsített Bayes-képlet és hozzávetőleges becsléseink segítségével:
P(H A) = A/(A+B), Ahol A = p a1 *p a2 *…*p an, B = p b1 *p b2 *…*p b n = (1 – p a1)*(1 – p a2)*… *(1 – p an).
1. táblázat. Az írás egyszerűsített (és hiányos) Bayes-becslése.

Így hipotetikus levelünk a „spam” hangsúllyal való összetartozás valószínűségét kapta. Dönthetünk úgy, hogy bedobjuk a levelet valamelyik kupacba? Határozzuk meg a döntési küszöböket:
- Feltételezzük, hogy a betű a H i kupachoz tartozik, ha P(H i) ≥ T.
- Egy betű nem tartozik a kupacba, ha P(H i) ≤ L.
- Ha L ≤ P(H i) ≤ T, akkor nem lehet döntést hozni.
Felveheti T = 0,95 és L = 0,05. Mivel a kérdéses levélre és 0,05< P(H A) < 0,95, и 0,05 < P(H В) < 0,95, то мы не сможем принять решение, куда отнести данное письмо: к спаму (H A) или к нужным письмам (H B). Можно ли улучшить оценку, используя больше информации?
Igen. Számítsuk ki az egyes bizonyítékok pontszámát más-más módon, ahogy Bayes is javasolta. Legyen:
F a a spam e-mailek száma;
F ai a tanúsítvánnyal rendelkező betűk száma én egy halom spamben;
F b a szükséges betűk teljes száma;
F bi a tanúsítvánnyal rendelkező betűk száma én egy csomó szükséges (releváns) levélben.
Ekkor: p ai = F ai /F a, p bi = F bi /F b. P(H A) = A/(A+B), P(H B) = B/(A+B), Ahol A = p a1 *p a2 *…*p an, B = p b1 *p b2 *…*p b n
Felhívjuk figyelmét, hogy a p ai és p bi bizonyítékszavak értékelése objektívvé vált, és emberi beavatkozás nélkül is kiszámítható.
2. táblázat: Pontosabb (de hiányos) Bayes-becslés egy levélben elérhető szolgáltatások alapján

Nagyon határozott eredményt kaptunk - nagy előnnyel a betű a kívánt betűk közé sorolható, hiszen P(H B) = 0,997 > T = 0,95. Miért változott az eredmény? Mivel több információt használtunk fel - figyelembe vettük az egyes halmok betűinek számát, és mellesleg sokkal pontosabban határoztuk meg a p ai és p bi becsléseket. Ugyanúgy határoztuk meg őket, mint maga Bayes, feltételes valószínűségek kiszámításával. Más szavakkal, p a3 annak a valószínűsége, hogy a „haver” szó megjelenik egy levélben, feltéve, hogy ez a betű már a H A spam kupachoz tartozik. Az eredmény nem váratott sokáig magára – úgy tűnik, nagyobb biztonsággal tudunk dönteni.
Bayes a vállalati csalás ellen
A Bayes-féle megközelítés egy érdekes alkalmazását írta le MAGNUS8.
Jelenlegi projektem (gyártóvállalati csalások felderítésére) a Bayes képlet segítségével határozza meg a csalás (csalás) valószínűségét több olyan tény megléte/hiánya esetén, amelyek közvetve a csalás lehetőségére vonatkozó hipotézis mellett tanúskodnak. Az algoritmus öntanuló (visszajelzéssel), azaz. újraszámítja együtthatóit (feltételes valószínűségét), ha a gazdaságbiztonsági szolgálat ellenőrzése során a csalást ténylegesen megerősíti vagy nem erősíti meg.
Valószínűleg érdemes azt mondani, hogy az algoritmusok tervezésénél az ilyen módszerek meglehetősen magas matematikai kultúrát igényelnek a fejlesztőtől, mert a legkisebb hiba a számítási képletek levezetésében és/vagy megvalósításában érvényteleníti és hiteltelenné teszi az egész módszert. A valószínűségi módszerek különösen hajlamosak erre, mivel az emberi gondolkodás nem alkalmazkodik a valószínűségi kategóriákkal való munkavégzéshez, és ennek megfelelően a köztes és végső valószínűségi paraméterek „fizikai jelentésének” nincs „láthatósága” és megértése. Ez a megértés csak a valószínűségszámítás alapfogalmainál létezik, és akkor csak nagyon óvatosan kell kombinálni és levezetni a bonyolult dolgokat a valószínűségszámítás törvényei szerint - a józan ész többé nem segít az összetett objektumok esetében. Ez különösen a valószínűségszámítás filozófiájáról szóló modern könyvek lapjain zajló meglehetősen komoly módszertani csatákhoz, valamint számos szofizmushoz, paradoxonhoz és furcsa rejtvényhez kapcsolódik ebben a témában.
Egy másik árnyalat, amivel szembesülnöm kellett, hogy sajnos szinte minden, ami a GYAKORLATBAN HASZNOSÍTÓBAN többé-kevésbé HASZNOS, ebben a témában angolul van írva. Az orosz nyelvű forrásokban többnyire csak egy jól ismert elmélet található, csak a legprimitívebb esetekre demonstrációs példákkal.
Az utolsó megjegyzéssel teljesen egyetértek. Például a Google, amikor valami olyasmit próbált találni, mint „a Bayes-féle valószínűség könyv”, nem produkált semmi érthetőt. Igaz, arról számolt be, hogy Kínában betiltottak egy bayesi statisztikákat tartalmazó könyvet. (Andrew Gelman statisztikaprofesszor a Columbia Egyetem blogján számolt be arról, hogy az Adatelemzés regresszióval és többszintű/hierarchikus modellekkel című könyvét Kínában betiltották. Az ottani kiadó arról számolt be, hogy "a könyvet a hatóságok nem hagyták jóvá különféle politikailag érzékeny okok miatt. anyag a szövegben.") Kíváncsi vagyok, vajon hasonló ok vezetett-e a Bayes-féle valószínűségről szóló könyvek hiányához Oroszországban?
Konzervativizmus az emberi információfeldolgozásban
A valószínűségek határozzák meg a bizonytalanság mértékét. A valószínűség, mind Bayes, mind megérzéseink szerint, egyszerűen egy szám nulla és a között, amely azt jelzi, hogy egy kissé idealizált személy milyen mértékben hiszi el az állítást igaznak. Az ok, amiért az embert némileg idealizálják, az az, hogy két egymást kizáró esemény valószínűségeinek összege meg kell, hogy egyenlő legyen bármelyik esemény bekövetkezésének valószínűségével. Az additív tulajdonság olyan következményekkel jár, hogy kevés valódi ember találkozhat mindegyikkel.
Bayes tétele az additív tulajdonság triviális következménye, vitathatatlan, és minden valószínűségszámító egyetért vele, legyen az Bayes-féle és egyéb. Ennek egyik módja a következő. Ha P(H A |D) annak a későbbi valószínűsége, hogy az A hipotézis egy adott D érték megfigyelése után következett be, P(H A) a korábbi valószínűsége egy adott D érték megfigyelése előtt, P(D|H A ) annak a valószínűsége, hogy adott D értéket akkor figyeljük meg, ha H A igaz, és P(D) egy adott D érték feltétlen valószínűsége, akkor
(1) P(H A |D) = P(D|H A) * P(H A) / P(D)
A P(D) legjobban normalizáló állandónak tekinthető, ami azt eredményezi, hogy az utólagos valószínűségek összeadódnak a vizsgált, egymást kölcsönösen kizáró hipotézisek kimerítő halmazához képest. Ha ki kell számolni, akkor ez így lehet:
De gyakrabban a P(D) ki van zárva, nem pedig kiszámítva. Ennek kiküszöbölésének egy kényelmes módja, ha Bayes tételét valószínűség-esély arány formává alakítjuk.
Tekintsünk egy másik hipotézist, a H B -t, amely kölcsönösen kizárja H A -t, és gondolja meg ugyanazt a megadott mennyiséget, amely megváltoztatta a véleményét H A -val kapcsolatban
(2) P(H B |D) = P(D|H B) * P(H B) / P(D)
Most osszuk el az 1. egyenletet a 2. egyenlettel; így lesz az eredmény:

ahol Ω 1 a H A-tól H B-ig tartó utólagos esély, Ω 0 az előzetes esély, L pedig a statisztikusok számára ismert valószínűségi arány. A 3. egyenlet Bayes tételének ugyanaz a releváns változata, mint az 1. egyenlet, és gyakran lényegesen hasznosabb, különösen a hipotéziseket tartalmazó kísérleteknél. A Bayes-pártiak azzal érvelnek, hogy Bayes tétele formálisan optimális szabály arra vonatkozóan, hogyan kell felülvizsgálni a véleményeket az új bizonyítékok fényében.
Arra vagyunk kíváncsiak, hogy összehasonlítsuk a Bayes-tétel által meghatározott ideális viselkedést az emberek tényleges viselkedésével. Hogy némi fogalmat adjunk arról, hogy ez mit jelent, próbáljunk meg egy kísérletet Önnel, mint tesztalanyal. Ez a táska 1000 póker zsetont tartalmaz. Két ilyen zacskóm van, az egyikben 700 piros és 300 blue chip van, a másikban 300 piros és 700 kék. Feldobtam egy érmét, hogy eldöntsem, melyiket használjam. Tehát, ha a véleményünk megegyezik, akkor a jelenlegi valószínűsége, hogy több piros chipset tartalmazó zacskót kap, 0,5. Most egy véletlenszerű kiválasztást végez, és minden chip után visszatér. 12 zsetonnal 8 pirosat és 4 kéket kapsz. Nos, mindazok alapján, amiket tud, mennyi a valószínűsége annak, hogy a táskába kerül a legtöbb piros? Nyilvánvaló, hogy magasabb, mint 0,5. Kérjük, ne folytassa az olvasást, amíg fel nem jegyezte pontszámát.
Ha olyan, mint egy átlagos tesztfelvevő, akkor a pontszáma 0,7 és 0,8 közötti tartományba esett. Ha azonban elvégeznénk a megfelelő számítást, akkor a válasz 0,97 lenne. Valóban nagyon ritka, hogy egy olyan személy, akinél korábban nem mutatták ki a konzervativizmus hatását, ilyen magas becslésre jut, még akkor is, ha ismerte Bayes tételét.
Ha a vörös chipek aránya a zacskóban az r, akkor az átvétel valószínűsége r piros chips és ( n –r) kék be n minták visszaküldéssel – p r (1–p)n-r. Tehát egy tipikus kísérletben egy zacskóval és pókerzsetonnal, ha NA azt jelenti, hogy a piros zsetonok aránya r AÉs NB– azt jelenti, hogy a részvény az rB, akkor a valószínűségi arány:

Bayes képletének alkalmazásakor csak a tényleges megfigyelés valószínűségét kell figyelembe venni, nem pedig más megfigyelések valószínűségét, amelyeket esetleg megtett volna, de nem. Ennek az elvnek széles körű következményei vannak a Bayes-tétel minden statisztikai és nem statisztikai alkalmazására; ez a bayesi érvelés legfontosabb technikai eszköze.
Bayesi forradalom
Barátai és kollégái valamiről beszélnek, amit "Bayes-tételnek" vagy "Bayes-szabálynak" hívnak, vagy valamiről, amit Bayes-féle érvelésnek hívnak. Nagyon érdekli őket ez, úgyhogy felmész az internetre, és találsz egy oldalt a Bayes-tételről, és... Ez egy egyenlet. És ennyi... Miért kelt ekkora lelkesedést a fejekben egy matematikai fogalom? Milyen „bayesi forradalom” zajlik a tudósok körében, és azt állítják, hogy még maga a kísérleti megközelítés is annak különleges eseteként írható le? Mi a titka, amit a bayesiek ismernek? Milyen fényt látnak?
A bayesi forradalom a tudományban azért nem következett be, mert egyre több kognitív tudós kezdte észrevenni, hogy a mentális jelenségeknek bayesi szerkezetük van; nem azért, mert a tudósok minden területen elkezdték használni a bayesi módszert; hanem azért, mert maga a tudomány Bayes tételének speciális esete; a kísérleti bizonyíték Bayes-féle bizonyíték. A bayesi forradalmárok azzal érvelnek, hogy amikor egy kísérletet végez, és olyan bizonyítékot szerez, amely „megerősíti” vagy „cáfolja” az elméletét, akkor ez a megerősítés vagy cáfolat a bayesi szabályok szerint történik. Például nemcsak azt kell figyelembe vennie, hogy elmélete megmagyarázhat egy jelenséget, hanem azt is, hogy vannak más lehetséges magyarázatok is, amelyek szintén megjósolhatják azt a jelenséget.
Korábban a legnépszerűbb tudományfilozófia a régi filozófia volt, amelyet a bayesi forradalom kiszorított. Karl Popper gondolata, hogy az elméleteket teljesen meg lehet hamisítani, de soha nem lehet teljesen ellenőrizni, a Bayes-szabályok másik speciális esete; ha p(X|A) ≈ 1 – ha az elmélet helyes előrejelzéseket ad, akkor a ~X megfigyelése nagyon erősen meghamisítja A-t. Másrészt, ha p(X|A) ≈ 1 és X-et figyelünk meg, ez nem erősíti meg erősen. az elmélet; esetleg más B feltétel is lehetséges, például p(X|B) ≈ 1, és amely mellett az X megfigyelés nem A mellett, hanem B mellett tesz tanúbizonyságot. Ha X megfigyelés határozottan megerősíti A-t, akkor az lenne a célunk, hogy nem tudni, hogy p(X|A) ≈ 1 és p(X|~A) ≈ 0, amit nem tudhatunk, mert nem tudunk minden lehetséges alternatív magyarázatot figyelembe venni. Például amikor Einstein általános relativitáselmélete felülmúlta Newton jól alátámasztott gravitációs elméletét, Newton elméletének összes előrejelzését Einstein előrejelzéseinek különleges esetévé tette.
Hasonló módon Popper azon állítása, miszerint egy eszmének meghamisíthatónak kell lennie, a bayesi valószínűség-megőrző szabály megnyilvánulásaként értelmezhető; ha az X eredmény pozitív bizonyíték az elméletre, akkor a ~X eredménynek bizonyos mértékig meg kell cáfolnia az elméletet. Ha megpróbálod az X-et és a ~X-et is úgy értelmezni, mint ami „megerősíti” az elméletet, a Bayes-szabályok szerint ez lehetetlen! Egy elmélet valószínűségének növelése érdekében olyan teszteknek kell alávetni, amelyek potenciálisan csökkenthetik annak valószínűségét; ez nem csupán egy szabály a sarlatánok azonosítására a tudományban, hanem a Bayes-féle valószínűségi tétel következménye. Másrészt téves Popper azon elképzelése, hogy csak hamisításra van szükség, megerősítésre nincs szükség. Bayes tétele azt mutatja, hogy a hamisítás nagyon erős bizonyíték a megerősítéshez képest, de a hamisítás továbbra is valószínűségi jellegű; nem szabályozzák alapvetően eltérő szabályok, és ily módon nem különbözik a megerősítéstől, ahogy azt Popper állítja.
Így azt találjuk, hogy a kognitív tudományok számos jelensége, plusz a tudósok által használt statisztikai módszerek, plusz maga a tudományos módszer, mind Bayes-tétel speciális esetei. Ez a bayesi forradalom.
Üdvözöljük a Bayes-féle összeesküvésben!
Irodalom a Bayes-valószínűségről
2. Bayes sok különböző alkalmazását írja le a közgazdasági Nobel-díjas Kahneman (és társai) egy csodálatos könyvben. Csak ennek a nagyon nagy könyvnek a rövid összefoglalójában 27-szer számoltam meg egy presbiteri lelkész nevének említését. Minimális képletek. (.. nagyon tetszett. Igaz, kicsit bonyolult, sok a matematika (és hol lennénk nélküle), de az egyes fejezetek (pl. 4. Tájékoztatás) egyértelműen a témához tartoznak. mindenkinek, még ha nehéz is a matematika, olvass el minden második sort, kihagyva a matematikát, és a hasznos gabonák után horgászva...
14. (2017. január 15-i kiegészítés), egy fejezet Tony Crilly könyvéből. 50 ötlet, amiről tudnod kell. Matematika.
A Nobel-díjas fizikus, Richard Feynman, amikor egy filozófusról beszélt különösen nagy önjelentőséggel, egyszer azt mondta: „Nem a filozófia mint tudomány irritál, hanem a körülötte létrejövő pompozíció. Bárcsak a filozófusok tudnának magukon nevetni! Bárcsak azt mondanák: „Azt mondom, hogy ez így van, de Von Lipcsei másnak gondolta, és ő is tud róla valamit.” Ha eszébe jutna tisztázni, hogy csak az övék .
Bayes képlet:A H i hipotézisek P(H i) valószínűségeit a priori valószínűségeknek - a kísérletek elvégzése előtti valószínűségeknek nevezzük.
A P(A/H i) valószínűségeket utólagos valószínűségeknek nevezzük – a tapasztalatok eredményeként finomított H i hipotézisek valószínűségei.
1. számú példa. A készülék kiváló minőségű alkatrészekből és normál minőségű alkatrészekből is összeállítható. Az eszközök mintegy 40%-a kiváló minőségű alkatrészekből készül. Ha az eszközt jó minőségű alkatrészekből állítják össze, megbízhatósága (a hibamentes működés valószínűsége) t idő alatt 0,95; ha normál minőségű alkatrészekből készül, akkor a megbízhatósága 0,7. A készüléket t időre tesztelték és hibátlanul működött. Határozza meg annak valószínűségét, hogy jó minőségű alkatrészekből készül.
Megoldás. Két hipotézis lehetséges: H 1 - a készüléket jó minőségű alkatrészekből állítják össze; H 2 - a készülék normál minőségű alkatrészekből van összeállítva. E hipotézisek valószínűsége a kísérlet előtt: P(H 1) = 0,4, P(H 2) = 0,6. A kísérlet eredményeként az A eseményt figyelték meg - a készülék hibátlanul működött t ideig. Ennek az eseménynek a feltételes valószínűsége a H 1 és H 2 hipotézisek szerint egyenlő: P(A|H 1) = 0,95; P(A|H2)=0,7. A (12) képlet segítségével meghatározzuk a H 1 hipotézis valószínűségét a kísérlet után:
![]()
2. példa. Két lövő egymástól függetlenül lő ugyanarra a célpontra, mindegyik egy lövést ad le. A cél eltalálásának valószínűsége az első lövésznél 0,8, a másodiknál 0,4. Lövés után egy lyukat fedeztek fel a célban. Feltéve, hogy két lövő nem találja el ugyanazt a pontot, határozza meg annak valószínűségét, hogy az első lövő eltalálja a célt.
Megoldás. Legyen A esemény – lövés után egy lyukat észlel a cél. A forgatás megkezdése előtt hipotézisek lehetségesek:
H 1 - sem az első, sem a második lövész nem talál, ennek a hipotézisnek a valószínűsége: P(H 1) = 0,2 · 0,6 = 0,12.
H 2 - mindkét lövő eltalál, P(H 2) = 0,8 · 0,4 = 0,32.
H 3 - az első lövöldöző eltalál, de a második nem, P(H 3) = 0,8 · 0,6 = 0,48.
H 4 - az első lövész nem talál, de a második eltalálja, P (H 4) = 0,2 · 0,4 = 0,08.
Az A esemény feltételes valószínűsége ezen hipotézisek szerint egyenlő:
A kísérlet után a H 1 és H 2 hipotézisek lehetetlenné válnak, a H 3 és H 4 hipotézisek valószínűségei
egyenlő lesz:
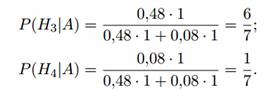
Tehát a legvalószínűbb, hogy a célt az első lövő találta el.
3. példa. A szerelőműhelyben egy villanymotort csatlakoztatnak a készülékhez. Az elektromos motorokat három gyártó szállítja. Raktáron vannak a nevezett gyárak villanymotorjai 19,6, illetve 11 darabos mennyiségben, amelyek a garanciális időszak végéig hiba nélkül üzemelhetnek 0,85, 0,76, illetve 0,71-es valószínűséggel. A dolgozó véletlenszerűen vesz egy motort, és felszereli a készülékre. Határozza meg annak valószínűségét, hogy egy beépített és a jótállási idő végéig hiba nélkül működő villanymotort az első, második vagy harmadik gyártó szállított.
Megoldás. Az első teszt a villanymotor kiválasztása, a második a villanymotor működése a garanciális időszak alatt. Vegye figyelembe a következő eseményeket:
A - az elektromos motor meghibásodás nélkül működik a jótállási időszak végéig;
H 1 - a telepítő átveszi a motort az első üzem gyártásából;
H 2 - a telepítő átveszi a motort a második üzem gyártásából;
H 3 - a telepítő átveszi a motort a harmadik üzem gyártásából.
Az A esemény valószínűségét a teljes valószínűségi képlet segítségével számítjuk ki:
A feltételes valószínűségeket a problémameghatározás határozza meg:
Keressük a valószínűségeket
Bayes-képletekkel (12) kiszámítjuk a H i hipotézisek feltételes valószínűségeit:

4. számú példa. Annak valószínűsége, hogy egy három elemből álló rendszer működése során az 1-es, 2-es és 3-as elemek meghibásodnak, aránya 3:2:5. Ezen elemek meghibásodásának észlelési valószínűsége 0,95; 0,9 és 0,6.
b) A feladat feltételei között a rendszer működése közben hibát észleltek. Melyik elem hibásodott meg nagy valószínűséggel?
Megoldás.
Legyen A kudarc esemény. Vezessünk be egy hipotézisrendszert H1 - az első elem meghibásodása, H2 - a második elem meghibásodása, H3 - a harmadik elem meghibásodása.
Megtaláljuk a hipotézisek valószínűségét:
P(H1) = 3/(3+2+5) = 0,3
P(H2) = 2/(3+2+5) = 0,2
P(H3) = 5/(3+2+5) = 0,5
A probléma feltételei szerint az A esemény feltételes valószínűsége egyenlő:
P(A|H1) = 0,95, P(A|H2) = 0,9, P(A|H3) = 0,6
a) Határozza meg annak valószínűségét, hogy hiba észlelhető a rendszerben!
P(A) = P(H1)*P(A|H1) + P(H2)*P(A|H2) + P(H3)*P(A|H3) = 0,3*0,95 + 0,2*0,9 + 0,5 *0,6 = 0,765
b) A feladat feltételei között a rendszer működése közben hibát észleltek. Melyik elem hibásodott meg nagy valószínűséggel?
P1 = P(H1)*P(A|H1)/ P(A) = 0,3*0,95 / 0,765 = 0,373
P2 = P(H2)*P(A|H2)/ P(A) = 0,2*0,9 / 0,765 = 0,235
P3 = P(H3)*P(A|H3)/ P(A) = 0,5*0,6 / 0,765 = 0,392
A harmadik elem a legnagyobb valószínűséggel.
A teljes valószínűség képletének levezetésénél azt feltételeztük, hogy a hipotézisek valószínűségei ismertek a kísérlet előtt. Bayes képlete lehetővé teszi a kezdeti hipotézisek újraértékelését új információk fényében, nevezetesen, hogy egy esemény történt. Ezért Bayes képletét hipotézisfinomító képletnek nevezik.
Tétel (Bayes-képlet).
Ha az esemény  csak az egyik hipotézissel fordulhat elő
csak az egyik hipotézissel fordulhat elő
 , amelyek az események teljes csoportját alkotják, akkor a hipotézisek valószínűsége feltéve, hogy az esemény
, amelyek az események teljes csoportját alkotják, akkor a hipotézisek valószínűsége feltéve, hogy az esemény  képlettel számolva történt
képlettel számolva történt
 ,
,
 .
.
Bizonyíték.
Bayes formulája vagy a hipotézisértékelés bayesi megközelítése fontos szerepet játszik a közgazdaságtanban, mert lehetővé teszi a vezetői döntések korrigálását, a statisztikai elemzésben vizsgált jellemzők ismeretlen eloszlási paramétereinek becslését stb.
Példa. Az elektromos lámpákat két gyárban gyártják. Az első üzem az elektromos lámpák teljes számának 60% -át, a második 40% -át állítja elő. Az első üzem termékei a szabványos lámpák 70% -át, a második - 80% -át tartalmazzák. Az üzlet mindkét gyár termékeit fogadja. A boltban vásárolt izzó szabványosnak bizonyult. Határozza meg annak valószínűségét, hogy a lámpát az első üzemben gyártották.
Írjuk fel a feladat feltételét a megfelelő jelölés bevezetésével.
Adott:
esemény  az, hogy a lámpa szabványos.
az, hogy a lámpa szabványos.
Hipotézis  az, hogy a lámpát az első üzemben gyártották
az, hogy a lámpát az első üzemben gyártották
Hipotézis  az, hogy a lámpát egy második üzemben gyártották
az, hogy a lámpát egy második üzemben gyártották
Lelet
 .
.
Megoldás.
5. Ismételt független tesztek. Bernoulli képlete
Nézzük a diagramot független tesztek vagy Bernoulli-séma, amelynek fontos tudományos jelentősége és sokféle gyakorlati alkalmazása van.
Hagyd előállítani  független vizsgálatok, amelyek mindegyikében előfordulhat valamilyen esemény
független vizsgálatok, amelyek mindegyikében előfordulhat valamilyen esemény  .
.
Meghatározás.
Tesztek
hívjákfüggetlen
, ha mindegyikben van esemény 
 , függetlenül attól, hogy az esemény megjelent-e vagy sem
, függetlenül attól, hogy az esemény megjelent-e vagy sem  más tesztekben.
más tesztekben.
Példa. A próbapadra 20 db izzólámpa került, melyeket 1000 órán keresztül terhelés alatt teszteltünk. Annak a valószínűsége, hogy a lámpa átmegy a teszten, 0,8, és független attól, hogy mi történt a többi lámpával.
Ebben a példában a tesztelés a lámpa 1000 órás terhelésálló képességének ellenőrzésére vonatkozik. Ezért a tesztek száma egyenlő  . Minden egyes kísérletben csak két eredmény lehetséges:
. Minden egyes kísérletben csak két eredmény lehetséges:

Meghatározás.
Ismételt független kísérletek sorozata, amelyek mindegyikében egy-egy esemény  azonos valószínűséggel történik
azonos valószínűséggel történik  , a tesztszámtól függetlenül hívjákBernoulli-séma.
, a tesztszámtól függetlenül hívjákBernoulli-séma.
Az ellenkező esemény valószínűsége  jelöljük
jelöljük
 , és mint fentebb bebizonyosodott,
, és mint fentebb bebizonyosodott,
Tétel.
A Bernoulli-séma feltételei mellett annak a valószínűsége, hogy at  független tesztelési esemény
független tesztelési esemény  fog megjelenni
fog megjelenni  alkalommal, a képlet határozza meg
alkalommal, a képlet határozza meg
Ahol  az elvégzett független vizsgálatok száma;
az elvégzett független vizsgálatok száma;
 az esemény előfordulásának száma
az esemény előfordulásának száma  ;
;
 esemény bekövetkezésének valószínűsége
esemény bekövetkezésének valószínűsége  külön tárgyalásban;
külön tárgyalásban;
 annak valószínűsége, hogy egy esemény nem következik be
annak valószínűsége, hogy egy esemény nem következik be  külön tárgyalásban;
külön tárgyalásban;
A teljes valószínűségi képlet levezetésénél azt feltételeztük, hogy az esemény A, amelynek valószínűségét meg kellett határozni, megtörténhet valamelyik esemény N 1 , N 2 , ... , N n, amely páronként összeférhetetlen események teljes csoportját alkotja. Ráadásul ezeknek az eseményeknek (hipotéziseknek) a valószínűsége előre ismert volt. Tételezzük fel, hogy egy kísérletet végeztek, melynek eredményeként az esemény A megérkezett. Ez a kiegészítő információ lehetővé teszi számunkra, hogy újraértékeljük a hipotézisek valószínűségét. N i, miután kiszámolta P(Hi/A).
vagy a teljes valószínűségi képlet segítségével azt kapjuk

Ezt a képletet Bayes formulának vagy hipotézistételnek nevezik. Bayes képlete lehetővé teszi, hogy „felülvizsgálja” a hipotézisek valószínűségét, miután az eseményt eredményező kísérlet eredménye ismertté válik A.
Valószínűségek Р(Н i)− ezek a hipotézisek a priori valószínűségei (a kísérlet előtt számítják ki). A valószínűségek P(H i /A)− ezek a hipotézisek utólagos valószínűségei (a kísérlet után számítják ki). Bayes képlete lehetővé teszi az utólagos valószínűségek kiszámítását az előző valószínűségekből és egy esemény feltételes valószínűségeiből A.
Példa. Ismeretes, hogy az összes férfi 5%-a és a nők 0,25%-a színvak. Az orvosi kártya száma alapján véletlenszerűen kiválasztott személy színvakságban szenved. Mennyi a valószínűsége, hogy férfi?
Megoldás. Esemény A– egy személy színvakságban szenved. A kísérlet elemi eseményeinek tere - egy személyt az orvosi kártya száma választ ki - Ω = ( N 1 , N 2 ) 2 eseményből áll:
N 1 - kiválasztanak egy férfit,
N 2 – egy nőt választanak ki.
Ezek az események hipotézisekként választhatók ki.
A probléma (véletlenszerű választás) feltételei szerint ezeknek az eseményeknek a valószínűsége azonos és egyenlő P(N 1 ) = 0.5; P(N 2 ) = 0.5.
Ebben az esetben annak feltételes valószínűsége, hogy egy személy színvakságban szenved, egyenlő:
R(A/N 1 ) = 0.05 = 1/20; R(A/N 2 ) = 0.0025 = 1/400.
Mivel ismert, hogy a kiválasztott személy színvak, azaz az esemény megtörtént, Bayes képletével újraértékeljük az első hipotézist:

Példa. Három egyforma kinézetű doboz van. Az első dobozban 20 fehér, a másodikban 10 fehér és 10 fekete, a harmadikban pedig 20 fekete golyó található. Egy véletlenszerűen kiválasztott dobozból fehér golyót veszünk. Számítsa ki annak a valószínűségét, hogy a golyót az első mezőből húzzák ki.
Megoldás. Jelöljük azzal A esemény - egy fehér labda megjelenése. Három feltevés (hipotézis) fogalmazható meg a doboz kiválasztásával kapcsolatban: N 1 ,N 2 , N 3 – az első, második és harmadik doboz kiválasztása.
Mivel bármelyik doboz kiválasztása egyaránt lehetséges, a hipotézisek valószínűsége megegyezik:
P(N 1 )=P(N 2 )=P(N 3 )= 1/3.
A probléma szerint annak a valószínűsége, hogy az első dobozból fehér golyót húzzunk
Annak valószínűsége, hogy fehér golyót húzzunk a második dobozból ![]()
Annak valószínűsége, hogy fehér golyót húzzunk a harmadik dobozból
A kívánt valószínűséget a Bayes-képlet segítségével találjuk meg:

A tesztek megismétlése. Bernoulli képlete.
N kísérletet hajtanak végre, amelyek mindegyikében előfordulhat A esemény, de előfordulhat, hogy nem, és az A esemény valószínűsége minden egyes kísérletben állandó, pl. tapasztalatról tapasztalatra nem változik. Már tudjuk, hogyan keressük meg egy kísérletben az A esemény valószínűségét.
Különösen érdekes az A esemény bizonyos számú (m-szeres) előfordulásának valószínűsége n kísérletben. Az ilyen problémák könnyen megoldhatók, ha a tesztek függetlenek.
Def. Számos tesztet hívnak független az A eseménytől , ha az A esemény valószínűsége mindegyikben nem függ más kísérletek eredményétől.
Annak P n (m) valószínűsége, hogy az A esemény pontosan m-szer bekövetkezik (nem bekövetkezik n-m alkalommal, esemény ) ebben az n próbában. Az A esemény nagyon különböző sorrendben jelenik meg m-szer).
![]() - Bernoulli képlet.
- Bernoulli képlet.
A következő képletek nyilvánvalóak:
Р n (m
P n (m>k) = P n (k+1) + P n (k+2) +…+ P n (n) - az A esemény bekövetkezésének valószínűsége több k-szer n próbában.
Hasznos oldal? Mentse el, vagy mondja el barátainak
Ha az esemény A csak akkor történhet meg, ha az események egyike kialakul összeférhetetlen események teljes csoportja, akkor az esemény valószínűsége A képlettel számítjuk ki
Ezt a képletet ún teljes valószínűségi képlet.
Tekintsük újra az összeférhetetlen események teljes csoportját, amelyek valószínűségét ![]() . Esemény A csak az általunk megnevezett események bármelyikével együtt történhet meg hipotéziseket. Ezután a teljes valószínűségi képlet szerint
. Esemény A csak az általunk megnevezett események bármelyikével együtt történhet meg hipotéziseket. Ezután a teljes valószínűségi képlet szerint
Ha az esemény A megtörtént, ez megváltoztathatja a hipotézisek valószínűségét ![]() .
.
A valószínűségi szorzás tételével
![]() .
.
Hasonlóan a többi hipotézishez is
![]()
A kapott képletet ún Bayes képlet (Bayes képlet). A hipotézisek valószínűségeit ún posterior valószínűségek, míg - előzetes valószínűségek.
Példa. Az üzlet három gyárból kapott új termékeket. Ezen termékek százalékos összetétele a következő: 20% - az első vállalkozás termékei, 30% - a második vállalkozás termékei, 50% - a harmadik vállalkozás termékei; továbbá az első vállalkozás termékeinek 10%-a a legmagasabb minőségű, a másodiknál 5%, a harmadiknál pedig 20%-a a legmagasabb osztályú termékeknek. Határozza meg annak valószínűségét, hogy egy véletlenszerűen vásárolt új termék a legjobb minőségű lesz.
Megoldás. Jelöljük azzal IN azt az esetet, amikor a legmagasabb minőségű termékek kerülnek vásárlásra, azokat az eseményeket jelöljük, amelyek az első, második és harmadik vállalkozáshoz tartozó termékek vásárlásából állnak.
Alkalmazhatja a teljes valószínűségi képletet, és jelölésünkben:

Ha ezeket az értékeket behelyettesítjük a teljes valószínűségi képletbe, megkapjuk a kívánt valószínűséget:
Példa. A három lövő közül az egyiket a lővonalhoz hívják, és két lövést ad le. Annak valószínűsége, hogy az első lövöldözéssel eltalálja a célt, 0,3, a másodiknál 0,5; a harmadiknak - 0,8. A célt nem találják el. Határozza meg annak valószínűségét, hogy a lövéseket az első lövő adta le.
Megoldás. Három hipotézis lehetséges:
Az első lövöldözőt a tűzvonalhoz hívják,
A második lövöldözőt a tűzvonalhoz hívják,
A harmadik lövőt a lővonalhoz hívják.
Mivel bármely lövész behívása a tűzvonalba ugyanúgy lehetséges ![]()
A kísérlet eredményeként a B esemény volt megfigyelhető - a lövések eldördülése után a célt nem találták el. Ennek az eseménynek a feltételes valószínűsége a felállított hipotézisek alapján egyenlő:

A Bayes-képlet segítségével a kísérlet után megtaláljuk a hipotézis valószínűségét:
Példa. Három automata gép dolgozza fel az azonos típusú alkatrészeket, amelyek feldolgozás után egy közös szállítószalagra kerülnek. Az első gép a hibák 2% -át állítja elő, a második - 7%, a harmadik - 10%. Az első gép termelékenysége háromszor nagyobb, mint a másodiké, a harmadiké pedig 2-szer kisebb, mint a másodiké.
a) Mekkora a hibaarány a futószalagon?
b) Mennyi az egyes gépekből származó alkatrészek aránya a szállítószalagon lévő hibás alkatrészek között?
Megoldás. Vegyünk véletlenszerűen egy alkatrészt a futószalagról, és vegyük figyelembe az A eseményt – az alkatrész hibás. Az alkatrész feldolgozási helyére vonatkozó hipotézisekhez kapcsolódik: – egy véletlenszerűen kiválasztott alkatrészt az -edik gépen dolgoztak fel, .
Feltételes valószínűségek (a problémafelvetésben százalékos formában vannak megadva):
A gépek termelékenysége közötti függőségek a következőket jelentik:
És mivel a hipotézisek egy teljes csoportot alkotnak, akkor .
A kapott egyenletrendszer megoldása után azt kapjuk, hogy: .
a) Annak teljes valószínűsége, hogy az összeszerelősorról véletlenszerűen vett alkatrész hibás.
Előző cikk: Mekkora a fénysebesség Következő cikk: Harmonikus rezgések Az oszcillációs frekvencia fizikai képlete