Таблицы границ доверительных интервалов для дисперсии. Доверительный интервал оценки генеральной дисперсии
Аннотация: Под временными рядами понимают экономические величины, зависящие от времени. При этом время предполагается дискретным, в противном случае говорят о случайных процессах, а не о временных рядах.
Модели стационарных и нестационарных временных рядов, их идентификация
Пусть Рассмотрим временной ряд . Пусть сначала временной ряд принимает числовые значения. Это могут быть, например, цены на батон хлеба в соседнем магазине или курс обмена доллара на рубли в ближайшем обменном пункте. Обычно в поведении временного ряда выявляют две основные тенденции - тренд и периодические колебания.
При этом под трендом понимают зависимость от времени линейного, квадратичного или иного типа, которую выявляют тем или иным способом сглаживания (например, экспоненциального сглаживания) либо расчетным путем, в частности, с помощью метода наименьших квадратов . Другими словами, тренд - это очищенная от случайностей основная тенденция временного ряда.
Временной ряд обычно колеблется вокруг тренда , причем отклонения от тренда часто обнаруживают правильность. Часто это связано с естественной или назначенной периодичностью, например, сезонной или недельной, месячной или квартальной (например, в соответствии с графиками выплаты заплаты и уплаты налогов). Иногда наличие периодичности и тем более ее причины неясны, и задача эконометрика - выяснить, действительно ли имеется периодичность .
Элементарные методы оценки характеристик временных рядов обычно достаточно подробно рассматриваются в курсах "Общей теории статистики" (см., например, учебники ), поэтому нет необходимости подробно разбирать их здесь. (Впрочем, о некоторых современных методах оценивания длины периода и самой периодической составляющей речь пойдет ниже.)
Характеристики временных рядов . Для более подробного изучения временных рядов используются вероятностно-статистические модели. При этом временной ряд рассматривается как случайный процесс (с дискретным временем) основными характеристиками являются математическое ожидание , т.е.
Дисперсия , т.е.
и автокорреляционная функция временного ряда
т.е. функция двух переменных, равная коэффициенту корреляции между двумя значениями временного ряда и .
В теоретических и прикладных исследованиях рассматривают широкий спектр моделей временных рядов. Выделим сначала стационарные
модели. В них совместные функции распределения ![]() для любого числа моментов времени , а потому и все перечисленные выше характеристики временного ряда не меняются со временем
. В частности, математическое ожидание и дисперсия
являются постоянными величинами, автокорреляционная функция
зависит только от разности . Временные ряды, не являющиеся стационарными, называются нестационарными
.
для любого числа моментов времени , а потому и все перечисленные выше характеристики временного ряда не меняются со временем
. В частности, математическое ожидание и дисперсия
являются постоянными величинами, автокорреляционная функция
зависит только от разности . Временные ряды, не являющиеся стационарными, называются нестационарными
.
Линейные регрессионные модели с гомоскедастичными и гетероскедастичными, независимыми и автокоррелированными остатками . Как видно из сказанного выше, основное - это "очистка" временного ряда от случайных отклонений, т.е. оценивание математического ожидания. В отличие от простейших моделей регрессионного анализа , рассмотренных в , здесь естественным образом появляются более сложные модели. Например, дисперсия может зависеть от времени. Такие модели называют гетероскедастичными , а те, в которых нет зависимости от времени - гомоскедастичными. (Точнее говоря, эти термины могут относиться не только к переменной "время", но и к другим переменным.)
Замечание . Как уже отмечалось в "Многомерный статистический анализ" , простейшая модель метода наименьших квадратов допускает весьма далекие обобщения, особенно в области системам одновременных эконометрических уравнений для временных рядов. Для понимания соответствующей теории и алгоритмов необходимо профессиональное владение матричной алгеброй. Поэтому мы отсылаем тех, кому это интересно, к литературе по системам эконометрических уравнений и непосредственно по временным рядам , в которой особенно много интересуются спектральной теорией, т.е. выделением сигнала из шума и разложением его на гармоники. Подчеркнем в очередной раз, что за каждой главой настоящей книги стоит большая область научных и прикладных исследований, вполне достойная того, чтобы посвятить ей много усилий. Однако из-за ограниченности объема книги мы вынуждены изложение сделать конспективным.
Системы эконометрических уравнений
Пример модели авторегрессии . В качестве первоначального примера рассмотрим эконометрическую модель временного ряда, описывающего рост индекса потребительских цен (индекса инфляции). Пусть - рост цен в месяц (подробнее об этой проблематике см. "Эконометрический анализ инфляции"). Тогда по мнению некоторых экономистов естественно предположить, что
| (6.1) |
где - рост цен в предыдущий месяц (а - некоторый коэффициент затухания, предполагающий, что при отсутствии внешний воздействий рост цен прекратится), - константа (она соответствует линейному изменению величины со временем), - слагаемое, соответствующее влиянию эмиссии денег (т.е. увеличения объема денег в экономике страны, осуществленному Центральным Банком) в размере и пропорциональное эмиссии с коэффициентом , причем это влияние проявляется не сразу, а через 4 месяца; наконец, - это неизбежная погрешность .
Модель (1), несмотря на свою простоту, демонстрирует многие характерные черты гораздо более сложных эконометрических моделей. Во-первых, обратим внимание на то, что некоторые переменные определяются (рассчитываются) внутри модели, как . Их называют эндогенными (внутренними) . Другие задаются извне (это экзогенные переменные). Иногда, как в теории управления, среди экзогенных переменных , выделяют управляемые переменные - те, с помощью которых менеджер может привести систему в нужное ему состояние.
Во-вторых, в соотношении (1) появляются переменные новых типов - с лагами, т.е. аргументы в переменных относятся не к текущему моменту времени, а к некоторым прошлым моментам.
В-третьих, составление эконометрической модели типа (1) - это отнюдь не рутинная операция. Например, запаздывание именно на 4 месяца в связанном с эмиссией денег слагаемом - это результат достаточно изощренной предварительной статистической обработки. Далее, требует изучения вопрос зависимости или независимости величин и . От решения этого вопроса зависит, как выше уже отмечалось, конкретная реализация процедуры метода наименьших квадратов .
С другой стороны, в модели (1) всего 3 неизвестных параметра, и постановку метода наименьших квадратов выписать нетрудно:
Проблема идентифицируемости . Представим теперь модель тапа (6.1) с большим числом эндогенных и экзогенных переменных , с лагами и сложной внутренней структурой. Вообще говоря, ниоткуда не следует, что существует хотя бы одно решение у такой системы. Поэтому возникает не одна, а две проблемы. Есть ли хоть одно решение (проблема идентифицируемости)? Если да, то как найти наилучшее решение из возможных? (Это - проблема статистической оценки параметров.)
И первая, и вторая задача достаточно сложны. Для решения обоих задач разработано множество методов, обычно достаточно сложных, лишь часть из которых имеет научное обоснование. В частности, достаточно часто пользуются статистическими оценками, не являющимися состоятельными (строго говоря, их даже нельзя назвать оценками).
Коротко опишем некоторые распространенные приемы при работе с системами линейных эконометрических уравнений.
Система линейных одновременных эконометрических уравнений . Чисто формально можно все переменные выразить через переменные, зависящие только от текущего момента времени. Например, в случае уравнения (6.1) достаточно положить
Тогда уравнение пример вид
| (6.2) |
Отметим здесь же возможность использования регрессионных моделей с переменной структурой путем введения фиктивных переменных. Эти переменные при одних значениях времени (скажем, начальных) принимают заметные значения, а при других - сходят на нет (становятся фактически равными 0). В результате формально (математически) одна и та же модель описывает совсем разные зависимости.
Косвенный, двухшаговый и трехшаговый методы наименьших квадратов . Как уже отмечалось, разработана масса методов эвристического анализа систем эконометрических уравнений. Они предназначены для решения тех или иных проблем, возникающих при попытках найти численные решения систем уравнений.
Одна из проблем связана с наличием априорных ограничений на оцениваемые параметры. Например, доход домохозяйства может быть потрачен либо на потребление, либо на сбережение. Значит, сумма долей этих двух видов трат априори равна 1. А в системе эконометрических уравнений эти доли могут участвовать независимо. Возникает мысль оценить их методом наименьших квадратов , не обращая внимания на априорное ограничение, а потом подкорректировать. Такой подход называют косвенным методом наименьших квадратов .
Двухшаговый метод наименьших квадратов состоит в том, что оценивают параметры отдельного уравнения системы, а не рассматривают систему в целом. В то же время трехшаговый метод наименьших квадратов применяется для оценки параметров системы одновременных уравнений в целом. Сначала к каждому уравнению применяется двухшаговый метод с целью оценить коэффициенты и погрешности каждого уравнения, а затем построить оценку для ковариационной матрицы погрешностей, После этого для оценивания коэффициентов всей системы применяется обобщенный метод наименьших квадратов .
Менеджеру и экономисту не следует становиться специалистом по составлению и решению систем эконометрических уравнений, даже с помощью тех или иных программных систем, но он должен быть осведомлен о возможностях этого направления эконометрики, чтобы в случае производственной необходимости квалифицированно сформулировать задание для специалистов-эконометриков.
От оценивания тренда (основной тенденции) перейдем ко второй основной задаче эконометрики временных рядов - оцениванию периода ( цикла ).
При построении эконометрической модели используются два типа данных:
- 1) данные, характеризующие совокупность различных объектов в определенный момент времени;
- 2) данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными моделями. Модели, построенные на основе второго типа данных, называются моделями временных рядов.
Временной ряд (ряд динамики) - это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
- 1) факторы, формирующие тенденцию ряда;
- 2) факторы, формирующие циклические колебания ряда;
- 3) случайные факторы.
Рассмотрим воздействие каждого фактора на временной ряд в отдельности.
Большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Все эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис. 4.1 показан гипотетический временной ряд, содержащий возрастающую тенденцию.
Также изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года (например, цены на сельскохозяйственную продукцию в летний период выше, чем в зимний; уровень безработицы в курортных городах в зимний период выше по сравнению с летним). При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка. На рис. 4.2 представлен гипотетический временной ряд, содержащий только сезонную компоненту.

Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень образуется как сумма среднего уровня ряда и некоторой (положительной или отрицательной) случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведен на рис. 4.3.

Очевидно, что реальные данные не следуют целиком и полностью из каких-либо описанных выше моделей. Чаще всего они содержат все три компоненты. Каждый их уровень формируется под воздействием тенденции, сезонных колебаний и случайной компоненты.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью временного ряда. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью временного ряда. Основная задача эконометрического исследования отдельного временного ряда - выявление и придание количественного выражения каждой из перечисленных выше компонент с тем, чтобы использовать полученную информацию для прогнозирования будущих значений ряда или при построении моделей взаимосвязи двух или более временных рядов.
Анализ временных рядов позволяет изучить показатели во времени. Временной ряд – это числовые значения статистического показателя, расположенные в хронологическом порядке.
Подобные данные распространены в самых разных сферах человеческой деятельности: ежедневные цены акций, курсов валют, ежеквартальные, годовые объемы продаж, производства и т.д. Типичный временной ряд в метеорологии, например, ежемесячный объем осадков.
Временные ряды в Excel
Если фиксировать значения какого-то процесса через определенные промежутки времени, то получатся элементы временного ряда. Их изменчивость пытаются разделить на закономерную и случайную составляющие. Закономерные изменения членов ряда, как правило, предсказуемы.
Сделаем анализ временных рядов в Excel. Пример: торговая сеть анализирует данные о продажах товаров магазинами, находящимися в городах с населением менее 50 000 человек. Период – 2012-2015 гг. Задача – выявить основную тенденцию развития.
Внесем данные о реализации в таблицу Excel:
На вкладке «Данные» нажимаем кнопку «Анализ данных». Если она не видна, заходим в меню. «Параметры Excel» - «Надстройки». Внизу нажимаем «Перейти» к «Надстройкам Excel» и выбираем «Пакет анализа».
Подключение настройки «Анализ данных» детально описано .
Нужная кнопка появится на ленте.

Из предлагаемого списка инструментов для статистического анализа выбираем «Экспоненциальное сглаживание». Этот метод выравнивания подходит для нашего динамического ряда, значения которого сильно колеблются.

Заполняем диалоговое окно. Входной интервал – диапазон со значениями продаж. Фактор затухания – коэффициент экспоненциального сглаживания (по умолчанию – 0,3). Выходной интервал – ссылка на верхнюю левую ячейку выходного диапазона. Сюда программа поместит сглаженные уровни и размер определит самостоятельно. Ставим галочки «Вывод графика», «Стандартные погрешности».

Закрываем диалоговое окно нажатием ОК. Результаты анализа:

Для расчета стандартных погрешностей Excel использует формулу: =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; ‘диапазон прогнозных значений’)/ ‘размер окна сглаживания’). Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3).
Прогнозирование временного ряда в Excel
Составим прогноз продаж, используя данные из предыдущего примера.
На график, отображающий фактические объемы реализации продукции, добавим линию тренда (правая кнопка по графику – «Добавить линию тренда»).
Настраиваем параметры линии тренда:

Выбираем полиномиальный тренд, что максимально сократить ошибку прогнозной модели.
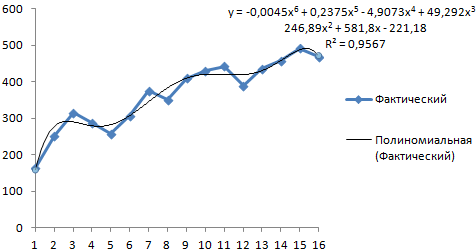
R2 = 0,9567, что означает: данное отношение объясняет 95,67% изменений объемов продаж с течением времени.
Уравнение тренда – это модель формулы для расчета прогнозных значений.

Получаем достаточно оптимистичный результат:
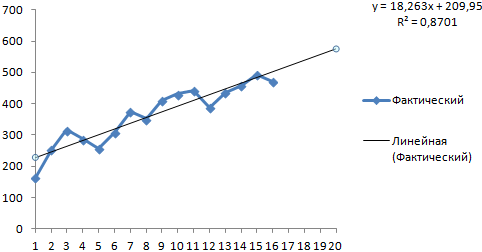
В нашем примере все-таки экспоненциальная зависимость. Поэтому при построении линейного тренда больше ошибок и неточностей.
Для прогнозирования экспоненциальной зависимости в Excel можно использовать также функцию РОСТ.

Для линейной зависимости – ТЕНДЕНЦИЯ.
При составлении прогнозов нельзя использовать какой-то один метод: велика вероятность больших отклонений и неточностей.
Элементы временного ряда
Определение 1
Временной ряд – это расположенные последовательно в хронологическом порядке показатели, которые характеризуют развитие того или иного явления во времени.
Основные задачи эконометрического исследования временных рядов:
- Прогнозирование будущих уровней динамических рядов;
- Исследование взаимосвязей между временными рядами.
Характеристиками временного ряда являются:
- Момент времени (конкретная дата) или период (год, квартал, неделя и т.д.), к которому относится статистическая информация;
- Непосредственно статистические данные – уровни временного ряда.
Значение уровня ряда зависит от влияния на него всей совокупности возможных факторов, которые можно подразделить на группы:
- Группа факторов, формирующих главную тенденцию ряда (компоненту тренда);
- Группа факторов, формирующих циклические колебания в рядах (циклическую компоненту). Компонента может быть конъюнктурной, т.е. связанной с большими циклами в экономике, и сезонной, связанной с внутригодовыми колебаниями.
- Группа случайных факторов, отражающих влияние большого числа факторов, не относящихся к циклическим или трендовым.
Тип связи между компонентами определяет вид модели, которая может быть аддитивной (сумма компонент) и мультипликативной (произведение компонент).
Определение структуры временного ряда
Эконометрические модели в большинстве своем являются динамическими. Это значит, что причинно-следственные связи между переменными моделируются во времени, а исходные значения – временные ряды. Временным рядом $x_t$ является ряд значений отдельного показателя за несколько последовательных временных промежутков.
Все временные ряды $x_t$ состоят из следующих составляющих:
- Тенденции, которая характеризует общую динамику исследуемого явления или процесса. Аналитическая тенденция – это некоторая функция времени, называемая трендом (T).
- Периодической или циклической составляющей, которая характеризует периодические или циклические колебания анализируемого явления. Колебания – это отклонения фактических значений от значений тренда. Например, продажи некоторых товаров подвержены сезонным колебаниям. Сезонными колебаниями являются периодические колебания, имеющие отдельный и постоянный период, который равен годовому промежутку. Колебания конъюнктуры происходят в условиях больших экономических циклов, период таких колебаний как правило равен нескольким годам.
- Случайной составляющей, являющейся результатом воздействия многих случайных факторов.
Чтобы определить состав компонентов в модели временного ряда, необходимо построить автокорреляционную функцию.
Автокорреляцией является корреляционная связь последовательных уровней одного и того же динамического ряда. Таким образом, автокорреляция представляет собой связь между рядами
$x_1, x_2, …, x_{n-1}, x_{1+l}, x_{2+l}, …, x_n$
где $l$ – это целое положительное число. Автокорреляция может изменяться коэффициентом автокорреляции (рисунок 1):
Рисунок 1. Формула расчета коэффициента автокорреляции. Автор24 - интернет-биржа студенческих работ
Лаг – это сдвиг во времени, которые позволяет определить порядок коэффициента. Если $l = 1$, то коэффициент автокорреляции будет первого порядка, при $l = 2$ коэффициент автокорреляции будет второго порядка. Необходимо учитывать, что при увеличении лага на одну единицу, количество пар значений, с помощью которых рассчитывается коэффициент автокорреляции, снижается на 1. Рекомендуемым максимальным порядком коэффициента является $n/4$.
После расчета коэффициентом автокорреляции, определяется величина лага, при котором наиболее высокая автокорреляция, тем самым выявляется структура временного ряда:
- При наиболее высоком значении коэффициента первого порядка в исследуемом ряду содержится только тенденция;
- При наиболее высоком значении коэффициента порядка $l$, в ряду содержатся колебания с соответствующим периодом.
Если ни один из коэффициентов не оказался значимым, то можно сделать один из двух выводов:
- Ряд не имеет циклических колебаний и тенденции, а его уровень определяется только лишь случайной компонентой;
- Ряд имеет существенную нелинейную тенденцию, чтобы выявить которую необходимо осуществить дополнительный анализ.
Замечание 1
Вся последовательность коэффициентов разных порядков называется автокорреляционной функцией временных рядов. График зависимостей значений коэффициентов от величины лага - это коррелограмма.
Одномерный временной ряд
В общем смысле временной ряд – это однопараметрическое семейство случайных значений $y_t = y(t_i)$, числовые характеристики и закон распределения которых могут зависеть от $t$.
Временные ряды, которые характеризуют динамику исследуемого явления, имеют большое различие с перекрестными данными, представляющими в статистике экономические явления. Основными отличиями являются:
- Значение каждого следующего уровня ряда напрямую зависит от значения предыдущего, другими словами, элементы ряда находятся в статистической зависимости. Например, численность населения государства в текущем году зависит от численности населения в прошлом.
- Местоположение каждого элемента временного ряда четко определено и не может произвольно изменяться: каждый из выборочных показателей строго соответствует моменту времени его анализа.
- Чем больше временной промежуток между уровнями ряда, тем большими будут различия в методике определения изучаемого показателя: функционирование одних факторов может прекращаться, а взамен образуются новые.
Все перечисленные особенности временных рядов обуславливают характерные только для них способы статистической обработки. Основными составляющими временного ряда являются: трендовая компонента, сезонная, циклическая и случайная.
Элементы временных рядов могут не представлять действие одновременно четырех факторов: при разных условиях применяются разные комбинации, однако, случайная компонента является обязательной для любых ситуаций.
МОСКОВСКИЙ ИНСТИТУТ УПРАВЛЕНИЯ
Специальность: Финансы и кредиты
Отделение: Заочное
Группа: РФК1
Курсовая работа
По Дисциплине: Эконометрика
На Тему: Временные ряды. Тренды. Автокорреляция.
Студент:
Руководитель:
Проверил:
Москва 2005г.
Введение . 3
История возникновения эконометрики как науки .. 5
Временные ряды. 7
Процесс белого шума .. 12
Процесс скользящего среднего .. 18
Нестационарные временные ряды .. 20
Тренд и его анализ. 24
.. 25
Сглаживание временных рядов . 28
Заключение . 32
Литература .. 33
Введение
Эконометрика – это наука, в которой на базе реальных статистических
данных строятся, анализируются и совершаются математические модели
реальных экономических явлений.
Одним из важнейших направлений эконометрики является построение
прогнозов по различным экономическим показателям.
· факторы, формирующие циклические колебания ряда (например,
сравнению с летним);
· случайные факторы.
Очевидно, что реальные данные чаще всего содержат все три компоненты. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью временного ряда. Если же временной ряд представлен как их произведение, то такая модель называется мультипликативной.
Под временным рядом (time series) понимается последовательность наблюдений значений некоторой переменной, произведенных через равные промежутки времени. Если принять длину такого промежутка за единицу времени (год, квартал, день и т. п.), то можно считать, что последовательные наблюдения x1, ..., xn произведены в моменты
t = 1, …, n.
Основная отличительная особенность статистического анализа временных рядов состоит в том, что последовательность наблюдений
x1, ..., xn рассматривается как реализация последовательности, вообще говоря, статистически зависимых случайных величин X1, ..., Xn, имеющих некоторое совместное распределение с функцией распределения
F(v1, v2, …, vn) = P{ X1 < v1, X2 < v2, ... , Xn < vn }.
Рассмотрим в основном временные ряды, у которых совместное распределение случайных величин X1, ..., Xn имеет совместную плотность распределения p(x1, x2, … , xn).
Чтобы сделать задачу статистического анализа временных рядов доступной для практического решения, приходится так или иначе ограничивать класс рассматриваемых моделей временных рядов, вводя те или иные предположения относительно структуры ряда и структуры его вероятностных характеристик. Одно из таких ограничений предполагает стационарность временного ряда.
Ряд xt, t = 1, …, n, называется строго стационарным (или стационарным в узком смысле), если для любого m (m < n) совместное распределение вероятностей случайных величин X t1…… X tm такое же, как и для X t1+ш…… X tm + I, при любых t1,…, tm и I, таких, что 1 ≤ t1, … , tm ≤ n и 1 ≤ t1+ д., … , tm+ I≤ n.
Другими словами, свойства строго стационарного временного ряда не изменяются при изменении начала отсчета времени. В частности, при m = 1 из предположения о строгой стационарности временного ряда xt следует, что закон распределения вероятностей случайной величины Xt не зависит от t, а значит, не зависят от t и все его основные числовые характеристики (если, конечно, они существуют), в том числе: математическое ожидание E (Xt) = Mи дисперсия D(Xt)= Ớ2.
Значение М. определяет постоянный уровень, относительно которого колеблется анализируемый временной ряд xt, а постоянная Ớ характеризует размах этих колебаний.
Одно из главных отличий последовательности наблюдений, образующих временной ряд, заключается в том, что члены временного ряда являются, вообще говоря, статистически взаимозависимыми. Степень тесноты статистической связи между случайными величинами Xt и Xt+ может быть измерена парным коэффициентом корреляции
font-size:14.0pt; line-height:150%">где
font-size:14.0pt; line-height:150%">Если ряд xt стационарный, то значение ![]() не зависит от t и является функцией только от ; мы будем использовать для него обозначение font-size:14.0pt; line-height:150%">font-size:14.0pt; line-height:150%">В частности,
не зависит от t и является функцией только от ; мы будем использовать для него обозначение font-size:14.0pt; line-height:150%">font-size:14.0pt; line-height:150%">В частности,
font-size:14.0pt; line-height:150%">Соответственно, для стационарного ряда и значение коэффициента корреляции
font-size:14.0pt; line-height:150%">.jpg" width="41" height="26">
так что
font-size:14.0pt; line-height:150%">В частности, font-size:14.0pt; line-height:150%">Практическая проверка строгой стационарности ряда xt на основании наблюдения значений x1, x2, …, xn в общем случае затруднительна. В связи с этим под стационарным рядом на практике часто подразумевают временной ряд xt, у которого
font-size:14.0pt; line-height:150%">Ряд, для которого выполнены указанные три условия, называют стационарным в широком смысле (слабо стационарным, стационарным второго порядка или ковариационно стационарным).
Если ряд является стационарным в широком смысле, то он не обязательно является строго стационарным. В то же время, и строго стационарный ряд может не быть стационарным в широком смысле просто потому, что у него могут не существовать математическое ожидание и/или дисперсия. (В отношении последнего примером может служить случайная выборка из распределения Коши.) Кроме того, возможны ситуации, когда указанные три условия выполняются, но, например, зависит от t. Ряд xt, t = 1, …, n, называется гауссовским, если совместное распределение случайных величин X1, ... , Xn является n-мерным нормальным распределением. Для
гауссовского ряда понятия стационарности в узком и в широком смысле совпадают.
В дальнейшем, говоря о стационарности некоторого ряда xt, мы (если не
оговаривается противное) будем иметь в виду, что этот ряд стационарен в широком смысле (так что у него существуют математическое ожидание и дисперсия). Итак, пусть xt – стационарный ряд c
font-size:14.0pt; line-height:150%">Поскольку в данном случае коэффициент измеряет корреляцию между членами одного и того же временного ряда, его принято называть коэффициентом автокорреляции (или просто автокорреляцией). По той же причине о ковариациях говорят как об автоковариациях..jpg" width="16" height="16">принято говорить об автокорреляционной функции font-size:14.0pt; line-height:150%"> Автокорреляционная функция безразмерна, т. е. не зависит от масштаба измерения анализируемого временного ряда. Ее значения могут изменяться в пределах от 1 до +1; при этом ρ(0) = 1. Кроме того, из стационарности ряда xt следует, , так что при анализе поведения автокорреляционных функций обычно ограничиваются рассмотрением только неотрицательных значений font-size:14.0pt; line-height:150%">График зависимости font-size:14.0pt; line-height:150%"> xt – стационарный временной ряд и
c – некоторая постоянная, то временные ряды
xt и (xt + c) имеют одинаковые коррелограммы.
Если предположить, что временной ряд описывается моделью стационарного
гауссовского процесса, то полное описание совместного распределения случайных величин X 1, ..., X n требует задания n+1 параметров:
или https://pandia.ru/text/79/393/images/image026_1.jpg" width="199" height="22 src=">
Это намного меньше, чем без требования стационарности, но все же больше, чем количество наблюдений. В связи с этим, даже для стационарных
гауссовских временных рядов приходится производить дальнейшее упрощение модели с тем, чтобы ограничить количество параметров, подлежащих оцениванию по имеющимся наблюдениям. Мы переходим теперь к рассмотрению некоторых простых по структуре временных рядов, которые, в то же время, полезны для описания эволюции во времени многих реальных экономических показателей.
Процесс белого шума
Процессом белого шума (“белым шумом”, “чисто случайным временным
рядом”) называют стационарный временной ряд xt, для которого
font-size:14.0pt; line-height:150%">Последнее означает, что при t ≠ s случайные величины Xt и Xs, соответствующие наблюдениям процесса белого шума в моменты t и s, некоррелированы.
В случае, когда Xt имеет нормальное распределение, случайные величины X 1, ..., X n взаимно независимы и имеют одинаковое нормальное распределение N(0, 2), образуя случайную выборку из этого распределения, т. е. ![]() .
.
Такой ряд называют гауссовским белым шумом.
В то же время, в общем случае, даже если некоторые случайные величины
X1, ... ,Xn взаимно независимы и имеют одинаковое распределение, то это еще не означает, что они образуют процесс белого шума, т. к. случайная величина Xt может просто не иметь математического ожидания и/или дисперсии (в качестве примера мы опять можем указать на распределение Коши).
Временной ряд, соответствующий процессу белого шума, ведет себя крайне нерегулярным образом из-за некоррелированности при t ≠ s случайных величин Xt и Xs. Это иллюстрирует приводимый ниже график смоделированной реализации гауссовского процесса белого шума (NOISE) с D(Xt) ≡ 0.04.
font-size:14.0pt; line-height:150%">В связи с этим процесс белого шума не годится для непосредственного моделирования эволюции большинства временных рядов, встречающихся в экономике.
В то же время, как мы увидим ниже, такой процесс является базой для построения более реалистичных моделей временных рядов, порождающих “более гладкие” траектории ряда. В связи с частым использованием процесса белого шума в дальнейшем изложении, мы будем отличать этот процесс от других моделей временных рядов, используя для него обозначение εt.
В качестве примера ряда, траектория которого похожа на реализацию процесса белого шума, можно указать, например, на ряд, образованный значениями темпов изменения (прироста) индекса Доу-Джонса в течение 1984 года (дневные данные).
График этого ряда имеет вид
font-size:14.0pt; line-height:150%">Заметим, однако, что здесь наблюдается некоторая асимметрия распределения вероятностей значений xt (скошенность этого распределения в сторону положительных значений), что исключает описание модели этого ряда как гауссовского белого шума.
Процесс авторегрессии
Одной из широко используемых моделей временных рядов является процесс авторегрессии (модель авторегрессии). В своей простейшей форме модель авторегрессии описывает механизм порождения ряда следующим образом:
Xt = a Xt – 1 + εt, t = 1, …, n,
где εt – процесс белого шума, имеющий нулевое математическое ожидание и
дисперсию font-size:14.0pt; line-height:150%">X0 – некоторая случайная величина,
а a ≠ 0 – некоторый постоянный коэффициент.
При этом
E(Xt) = a E(X t – 1),
так что рассматриваемый процесс может быть стационарным только если E(Xt) = 0 для всех t = 0, 1, …, n.
Xt = a X t – 1 + εt = a (a Xt –2 + εt–1) + εt = a2 Xt–2 + a εt–1 + εt = … =
= a t X0 + a t –1 ε1 + a t–2 ε2 + … + εt,
Xt–1 = a Xt–2 + εt–1 = a t–1 X0 + a t–2 ε1 + a t–3 ε2 + … + εt–1 ,
Xt–2 = a Xt–3 + εt–2 = a t–2 X0 + a t–3 ε1 + a t–4 ε2 + … + εt–2,
…
X1 = a X0 + ε1.
Если случайная величина X0 не коррелирована со случайными величинами ε1, ε2,
…, εn, то отсюда следует, что
font-size:14.0pt; line-height:150%">Таким образом, механизм порождения последовательных наблюдений, заданный соотношениями
Xt = a Xt–1 + εt, t = 1, …, n,
порождает стационарный временной ряд, если a < 1 ; случайная величина X0 не коррелирована со случайными величинами ε1, ε2, …,εn ;
font-size:14.0pt; line-height:150%">Рассмотренная модель порождает (при указанных условиях) стационарный ряд, имеющий нулевое математическое ожидание. Однако ее можно легко распространить и на временные ряды yt с ненулевым математическим ожиданием , полагая, что
указанная модель относится к центрированному ряду ![]()
font-size:14.0pt; line-height:150%">Поэтому без ограничения общности можно обойтись в текущем рассмотрении моделями авторегрессии, порождающими стационарный процесс с нулевым средним.
Продолжая рассмотрение для ранее определенного процесса Xt (с нулевым математическим ожиданием), заметим, что для него
font-size:14.0pt; line-height:150%">и при значениях a > 0, близких к 1, между соседними наблюдениями имеется сильная положительная корреляция, что обеспечивает более гладкий характер поведения траекторий ряда по сравнению с процессом белого шума. При a < 0 процесс авторегрессии, напротив, имеет менее гладкие реализации, поскольку в этом случае проявляется тенденция чередования знаков последовательных наблюдений.
Следующие два графика демонстрируют поведение смоделированных реализаций временных рядов, порожденных моделями авторегрессии ε
при a = 0.8 (первый график) и a = – 0.8 (второй график).
https://pandia.ru/text/79/393/images/image040_0.jpg" width="69" height="24">
Более того, статистические данные о поведении ряда до момента t = 0 могут
отсутствовать вовсе, так что значение x0 является просто некоторой наблюдаемой числовой величиной. В обоих случаях ряд Xt уже не будет стационарным даже при a.
Процесс скользящего среднего
Еще одной простой моделью порождения временного ряда является процесс скользящего среднего порядка q (MA(q)). Согласно этой модели,
font-size:14.0pt; line-height:150%">При этом для обеспечения стационарности необходимо и достаточно, чтобы параметры по обсолютной величине был меньше еденицы (или, что то же, чтобы корень характеристического уравнения 1- font-size:14.0pt; line-height:150%">font-size:14.0pt; line-height:150%">Смешанный процесс авторегрессии – скользящего среднего (процесс
Процесс Xt с нулевым математическим ожиданием, принадлежащий такому классу процессов, характеризуется порядками p и q его AR и МA составляющих и обозначается как процесс ARMA(p, q) (autoregressive moving average, mixed autoregressive moving average). Более точно, процесс Xt с нулевым математическим ожиданием принадлежит классу ARMA(p, q), если
font-size:14.0pt; line-height:150%">где a(L) и b(L) имеют тот же вид, что и в определенных ранее моделях AR(p) и MA(q). Если процесс имеет постоянное математическое ожидание , то он является процессом типа ARMA(p, q), если
font-size:14.0pt; line-height:150%">Отметим следующие свойства процесса
Процесс стационарен, если все корни уравнения a(z) = 0 лежат вне единичного
круга z ≤ 1.
Если процесс стационарен, то существует эквивалентный ему процесс
font-size:14.0pt; line-height:150%">Если все корни уравнения b(z) = 0 лежат вне единичного круга z ≤ 1
(условие обратимости), то существует эквивалентное представление
font-size:14.0pt; line-height:150%">Отсюда вытекает, что стационарный процесс ARMA(p, q) всегда можно
аппроксимировать процессом скользящего среднего достаточно высокого порядка, а
при выполнении условия обратимости его можно также аппроксимировать процессом авторегрессии достаточно высокого порядка.
В экономике многие временные ряды являются агрегированными. Из указанного выше факта вытекает, что если каждая из компонент отвечает простой модели AR, то при независимости этих компонент их сумма будет ARMA процессом.
Нестационарные временные ряды
В экономической практике принято рассматривать два основных типа нестационарных временных рядов:
Случайное блуждание (со сдвигом)
font-size:14.0pt; line-height:150%"> font-size:14.0pt; line-height:150%">Вторым основным типом является ряд вида:
Хt = https://pandia.ru/text/79/393/images/image054_1.gif" width="13" height="15 src=">t
Такие ряды называются также временными рядами с детерминистическим трендом.
|

200 |
150 |
100 |
50 |
Рис. Нестационарный временной ряд с детерминистическим трендом.
Рассмотрим временной ряд со стохастическим трендом.
Yt = https://pandia.ru/text/79/393/images/image054_1.gif" width="13" height="15 src=">t
Данное уравнение является частным случаем более общей модели
Yt = https://pandia.ru/text/79/393/images/image053_1.gif" width="16" height="15 src="> Yt-1 + font-size:14.0pt; line-height:150%">В зависимости от значения font-size:14.0pt; line-height:150%">|а| < 1 - процесс является стационарным;
|а| font-size:14.0pt; line-height:150%">При |а| >1 процесс становится «взрывным», т. е. шок, произошедший в системе в момент времени t, будет иметь более сильное влияние на нее в момент времени t+1, еще более сильное – в момент t+2 и т. д.
На рисунке изображены процессы нестационарных временных рядов с коэффициентом >1. Рисунок A
font-size:14.0pt; line-height:150%">Показывает первые 250, а
Рисунок Б. – первые 450 неблюдений одного и того же процесса. . Видно, как с увеличением числа наблюдений усиливается
взрывной» характер процесса.
Рисунок Б.
|

180 160 140 120 100 80 60 40 20 |
О450
Аналогичные тенденции прослеживаются для процессов с коэффициентом < -1.
Такого рода процессы (а также процесс с коэффициентом = -1 редко соотвествуют экономическим данным, поэтому, как правило, основной упор делается на рассмотрении процессов, имеющих единичный корень, - т. е. случая, когда =1.
Тренд и его анализ.
Тренд или тенденция временного ряда – это несколько условное
понятие. Под трендом понимают закономерную, неслучайную
составляющую временного ряда (обычно монотонную), которая может
быть вычислена по вполне определенному однозначному правилу. Тренд
временного ряда часто связан с действием физических законов или
каких-либо других объективных закономерностей. Однако, вообще
говоря, нельзя однозначно разделить случайный процесс или
временной ряд на регулярную часть (тренд) и колебательную часть
(остаток). Поэтому обычно предполагают, что тренд - это некоторая
функция простого вида (линейная, квадратичная и т. п.), описывающая
“поведение в целом” ряда или процесса. Если выделение такого
тренда упрощает исследование, то предположение о выбранной форме
тренда считается допустимым.
Для временного ряда уравнение линейного тренда имеет вид
font-size:14.0pt; line-height:150%"> При r>0 говорят о положительном тренде (с течением времени
значения временного ряда имеет тенденцию возрастать), при r<0 об
отрицательном (тенденция убывания). При r, близких к нулю, иногда
говорят о боковом тренде. Как было сказано выше, для случая, когда
t=1,2,3,...n, имеем:
font-size:14.0pt; line-height:150%">однако на практике не стоит отдельно вычислять r и уX и только
потом подставлять их в уравнение тренда. Лучше прямо в формуле
тренда произвести сокращения, после которых она примет вид:
font-size:14.0pt; line-height:150%"> После выделения линейного тренда нужно выяснить, насколько он
значим. Это делается с помощью анализа коэффициент корреляции.
Дело в том, что отличие коэффициента корреляции от нуля и тем
самым наличие реального тренда (положительного или отрицательного)
может оказаться случайным, связанным со спецификой
рассматриваемого отрезка временного ряда. Другими словами, при
анализе другого набора экспериментальных данных (для того же
временного ряда) может оказаться, что полученная при этом оценка
намного ближе к нулю, чем исходная (и, возможно, даже имеет другой
знак), и говорить о реальном тренде тут уже становится трудно.
Автокорреляция уровней временного ряда
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда.
Количественно ее можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько шагов во времени.
Формула для расчета коэффициента автокорреляции имеет вид:
font-size:14.0pt; line-height:150%">где
font-size:14.0pt; line-height:150%">Эту величину называют коэффициентом автокорреляции уровней ряда первого порядка, так как он измеряет зависимость между соседними уровнями ряда и .
Аналогично можно определить коэффициенты автокорреляции второго и более высоких порядков. Так, коэффициент автокорреляции второго порядка характеризует тесноту связи между уровнями и font-size:14.0pt; line-height:150%"> font-size:14.0pt; line-height:150%">где
font-size:14.0pt; line-height:150%">Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается. Считается целесообразным для обеспечения статистической достоверности коэффициентов автокорреляции использовать правило – максимальный лаг должен быть не больше .
Свойства коэффициента автокорреляции.
Он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной (или близкой к линейной) тенденции. Для некоторых временных рядов, имеющих сильную нелинейную тенденцию (например, параболу второго порядка или экспоненту), коэффициент автокорреляции уровней исходного ряда может приближаться к нулю.
По знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда. Большинство временных рядов экономических данных содержат положительную автокорреляцию уровней, однако при этом могут иметь убывающую тенденцию.
Последовательность коэффициентов автокорреляции уровней первого, второго и т. д. порядков называют автокорреляционной функцией временного ряда. График зависимости ее значений от величины лага (порядка коэффициента автокорреляции) называется коррелограммой.
Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а следовательно, и лаг, при котором связь между текущим и предыдущими уровнями ряда наиболее тесная, т. е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка , то ряд содержит циклические колебания с периодичностью в font-size:14.0pt; line-height:150%">рассматривается как указание на значимость корреляции с
соответствующим лагом.
Сглаживание временных рядов
Сглаживание временного ряда используется для удаления из него
высокочастотных компонент (которые обычно являются
несущественными, так как вызваны случайными факторами). Один из
простейших методов сглаживания - метод скользящих или подвижных
средних (MA в англоязычной нотации), он является одним из наиболее
старых и широко известных. Этот метод основан на переходе от
начальных значений временного ряда к их средним значениям на
некотором заданном интервале времени (длина которого называется
шириной окна). Этот интервал времени как бы скользит вдоль ряда, с
чем и связано название метода. В каждый момент этого скольжения мы
видим только часть ряда, чем и вызвана “оконная” терминология.
Полученный в результате такого сглаживания новый временной
ряд обычно ведет себя более регулярно (гладко), что связано с
удалением в процессе сглаживания резких случайных отклонений,
попадающих в окно. Сглаживание полезно применять даже в самом
начале исследования временного ряда, так как при этом часто
удается прояснить вопрос о наличии и характере тренда, а также
выявить сезонные колебания.
Несколько слов нужно сказать о сезонных колебаниях. Они
проявляются во многих временных рядах, в частности, в экономике,
метеорологии. Сезонными колебаниями называют все такие изменени,
которые соответствуют определенному (почти) строго периодическому
ритму (не обязательно равному одному году, как для обычных
сезонов), присущему Вселенной, природе или человеческой
деятельности. Такая периодичность может ярко проявляться в
процессах человеческой деятельности, например, в изменениях объема
перевозок местным транспортом в последние дни каждой недели или же
утром и вечером в течение каждого дня, в росте ошибок при
выполнении производственных операций по понедельникам и др. Но
наиболее типичные сезонные колебания связаны именно со сменой
сезонов года. Они затрагивают огромное число параметров жизни
человека (как современного, так и в древности). Обычно при
исследовании временных рядов стремятся выделить сезонные колебания
для того, чтобы их изолировать и изучить другие, более сложные
периодические компоненты.
Простейшее сглаживание методом MA с шириной окна 2m+1
производится по следующим формулам:
x*k=(xk-m+xk-m+1+...+xk+xk+1+...+xk+m)/2m+1.
Выбор ширины окна диктуется содержательными сображениями,
связанными с предполагаемым периодом сезонных колебаний или
с желательным исключением определенного рода высокочастотных
колебаний. На практике обычно при отсутствии сезонности ширину
окна берут равной 3, 5 или 7. Не рекомендуется брать окно шире,
чем в четверть числа анализируемых данных. Чем шире окно, тем
больше колебательных компонент будет исключено и тем более гладкий
вид полученного при сглаживании ряда. Однако при слишком больших
окнах полученный ряд уже значительно отличается от исходного,
теряются многие индивидуальные особенности и ряд все более
приближается к постоянному. Если взять ширину окна максимально
возможной (равной общему числу данных значений x1,x2,...), то
приходим просто к постоянной величине, равной среднему значению
всех этих xi.
Подвижные средние могут, к сожалению, искажать кратковременные колебания и порождать фиктивные гармонические
компоненты при гармоническом анализе временных рядов.
Имеются различные модификации метода MA. В некоторых из них
используются более сложные методы усреднения (с некоторыми весами
и др.), которые подчеркивают большую или меньшую значимость
отдельных слагаемых. Например, часто используемое экспоненциальное
сглаживание основано на приписывании больших весов непосредственно предшествующим значениям. Этот подход очень широко распространен в социологии, экономике и других дисциплинах.
В настоящее время метод MA (с различными модификациями)
реализован во всех статистических пакетах программ, а также в
многих специализированных программах, предназначенных для
обработки экономической и деловой информации.
Для случайных процессов тоже имеются разнообразные методы
сглаживания. Здесь число методов чрезвычайно велико, это связано с
тем, что усреднение может производиться с помощью интегрирования с
некоторой весовой функцией, которую можно выбирать достаточно
произвольно. Поэтому окно здесь задается не только своей шириной,
а и видом усредняющей функции. Правильный выбор окна представляет собой весьма непростую задачу, этому посвящена обширная литература. Прямоугольное окно (используемое в классическом варианте метода MA) имеет целый ряд недостатков, которые в классической теории рядов Фурье связывают с явлением Гиббса, в технике именуемом вытеканием мощности. При исследовании случайных процессов часто говорят не о сглаживании, а о фильтрации (или о коррекции, очистке спектра), причем в области высоких частот
говорят о применении фильтра высоких частот (ФВЧ), а в области
низких частот – о фильтре низких частот (ФНЧ). Такого рода
терминология принята, в частности, в теории распознавания сигналов
и, вообще, в теории связи.
Другой (терминологически, но не по существу) подход к
сглаживанию временных рядов и случайных процессов основан на
модификации спектра. Если в спектре ряда просто полностью удалить
высокочастотные компоненты, то получится новый ряд, который ведет
себя более регулярно. Такого рода вычисление возможны только при
наличии компьютера и специальной программы для работы с рядами и
преобразованиями Фурье. Эти программы входят в состав большинства
универсальных математических пакетов (Mathcad, Matlab, Maple,
Mathematica) и многих статистических пакетов.
Заключение
Эконометрика – это наука, которая дает количественное выражение
взаимосвязей экономических явлений и процессов. Эта наука возникла в результате взаимодействия и объединения трех компонент: экономической теории, статистических и экономических методов. Становление и развитие эконометрики происходили на основе так называемой высшей статистики, когда в уравнение регрессии начали включаться переменные не только в первой, но и во второй степени. В ряде случаев это необходимо для отражения свойства оптимальности экономических переменных, т. е. наличия значений, при которых достигается минимальное или максимальное воздействие на зависимую переменную. Таково, например, влияние внесения в почву удобрений на урожайность: до определенного уровня насыщение почвы удобрениями способствует росту урожайности, а по достижении оптимального уровня насыщения удобрениями его дальнейшее наращивание не приводит к росту урожайности и даже может вызвать ее снижение.
Описание экономических систем математическими методами, или эконометрика, дает заключение о реальных объектах и связях по результатам выборочного обследования или моделирования. Вместе с тем, чтобы сделать вывод о том, какие из полученных результатов являются достоверными, а какие сомнительными или просто необоснованными, необходимо уметь оценивать их надежность и величину погрешности. Все перечисленные аспекты и составляют содержание эконометрики как науки.
Таким образом, сердцевиной познания в экономике является эксперимент, предполагающий либо непосредственное наблюдение (измерение), либо математическое моделирование.
Литература
Основная:
1. Эконометрика: Учебник / Под ред. . – М.: Финансы и статистика, 2002. – 344 с.
2. Практикум по эконометрике: Учебн. пособие / Под ред. . – М.: Финансы и статистика, 2003. – 192 с.
3. Эконометрика в вопросах и ответах /учебное пособие, Москва 2005 . Изд-во Проспект, 208с.
4. , Путко: Учебник для вузов / Под ред. проф. . – М.: ЮНИТИ-ДАНА, 2002. – 311 с.
5. , Пересецкий. Начальный курс: Учебник. – М.: Дело, 2001. – 400 с.
6. Эконометрия / Москва «Финансы и статистика» 2001, -304с.
Предыдущая статья: Чему равна скорость света Следующая статья: Гармонические колебания Физика формула частоты колебаний